How to Train ChatGPT on Your Private Business Data for a 2026 Growth Strategy
Learn how to use Retrieval-Augmented Generation (RAG) and vector embeddings to turn ChatGPT into a proprietary marketing brain using your internal business data.
By 2026, the novelty of generic AI has worn off. Every competitor in your niche is already using large language models (LLMs) to draft blog posts and summarize meeting notes. The real competitive advantage no longer lies in using AI, but in proprietary intelligence—training AI on the data that only you possess. If your AI doesn't know your 2025 financial performance, your brand's specific tone of voice from 5,000 Gmail threads, or the nuanced cultural history of your Slack channels, you're essentially driving a high-performance vehicle on generic fuel.
This guide provides a technical yet growth-focused playbook on how to implement Retrieval-Augmented Generation (RAG) and vector embeddings to turn ChatGPT into a custom marketing brain that deeply understands your company's DNA. We are moving beyond simple prompts into a world where your AI is a teammate, not just a tool.
The 'Intern with a PhD' Framework: Why Generic LLMs Fail
Discover why AI is like an exceptionally smart intern with a PhD.
To understand why you need to train AI on your own data, you must understand the two primary limitations of modern LLMs: knowledge cut-offs and context windows. As AI strategist Dharmesh Shah notes in his framework for the AI-first world, an LLM is like an intern with a PhD in everything. They have read the entire public internet, they are exceptionally smart, but they show up for the first day of work knowing nothing about your specific business.
If you ask a frontier model about your top competitors, it might give you a generic list based on data from two years ago. It won't know about the secret pivot you made last quarter unless you provide that context. This is where the context window comes in. Imagine a sheet of paper that can only hold a certain number of words—that is your context window. In 2026, while frontier models have windows of 100,000 to 200,000 tokens (roughly the size of a book), an average business repository is far larger.
"The intern knows everything about everything that was publicly accessible, but they show up for the first day of work knowing nothing about your business. You have to give them the right documents to read at the right time."
Retrieval-Augmented Generation (RAG) vs. Vector Embeddings
Learn how vector databases allow AI to access your private business documents.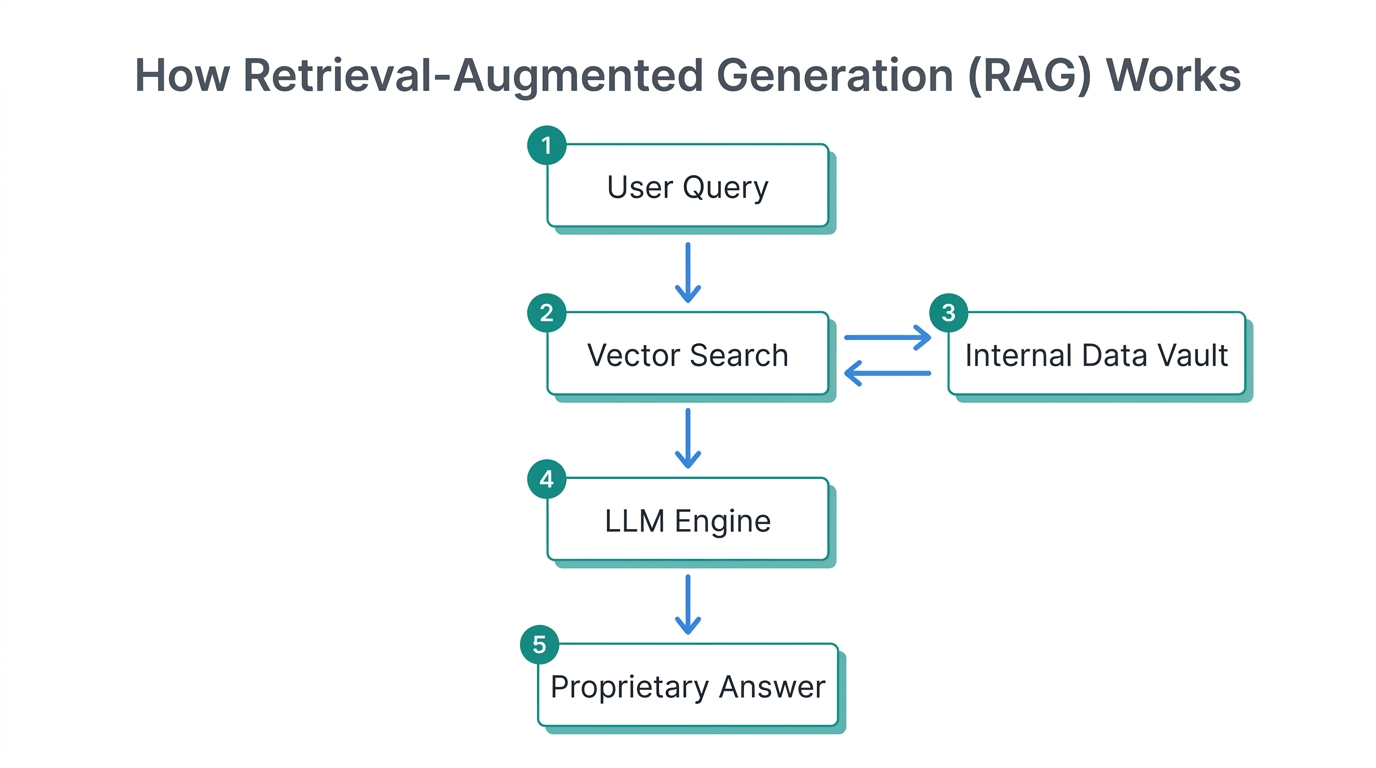
To solve the context window problem, we use Retrieval-Augmented Generation (RAG). Instead of trying to teach the AI everything at once, we build a system that fetches only the most relevant information for a specific query and stuffs it into the context window temporarily.
This process relies on vector embeddings. An embedding algorithm takes a piece of text—an email, a PDF, a spreadsheet—and converts it into a mathematical coordinate in a high-dimensional space. In this numerical map, documents with similar meanings are placed close together.
| Feature | Generic AI (Standard GPT) | Proprietary AI (RAG-Enabled) |
|---|---|---|
| Knowledge Source | Public internet data (Static) | Internal docs, Slack, Email (Dynamic) |
| Accuracy | Prone to hallucinations on niche topics | High; grounded in your specific data |
| Privacy | Data may be used for training (if not opted out) | Secure, private vector database |
| Up-to-Date | Locked to training cut-off date | Real-time access to latest files |
When you ask your custom brain, "What were the winning arguments for our last product launch?", the system doesn't search for keywords. It performs a semantic search in your vector store, finds the five most relevant emails or strategy docs, and says to ChatGPT: "Based on these five specific documents, answer the user's question."
Step 1: Preparing Your Internal Data for the AI Brain
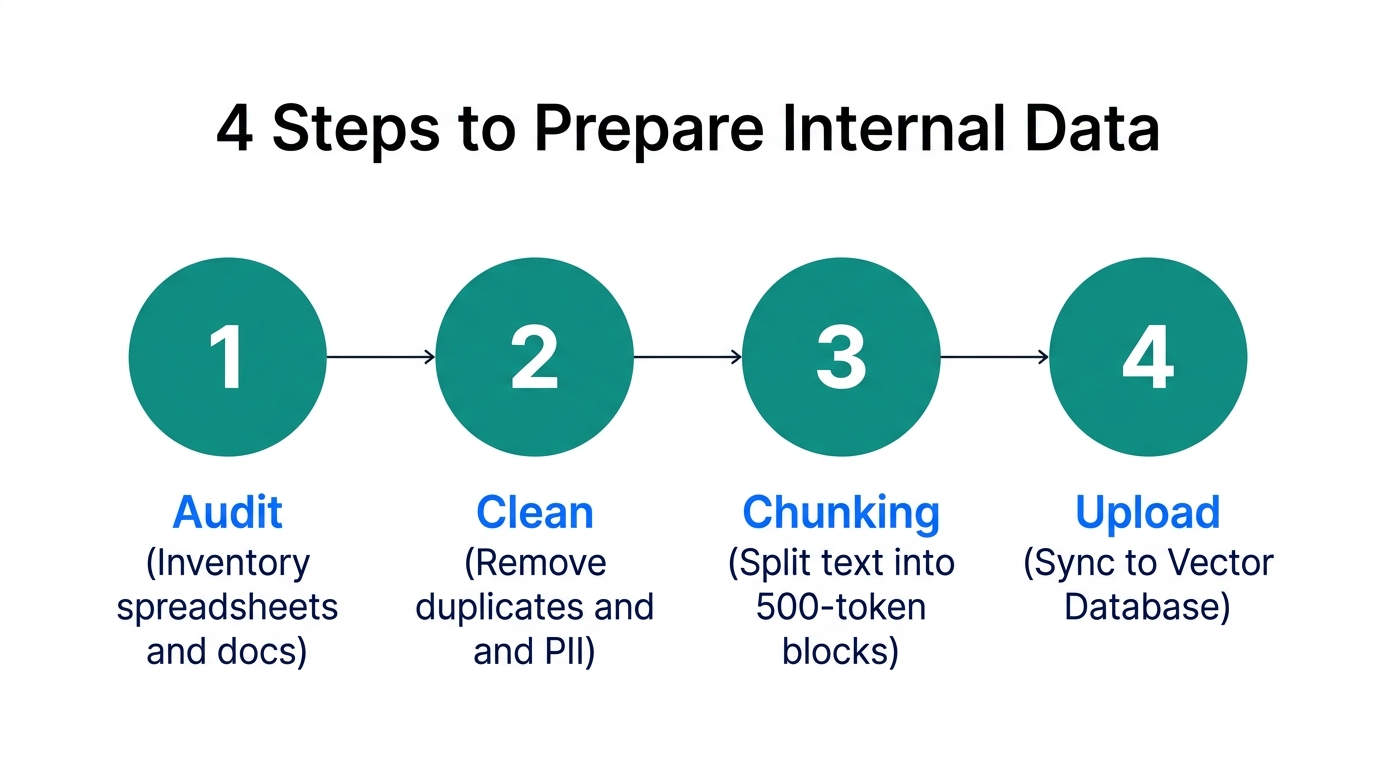
The quality of your AI's output is strictly gated by the quality of your data input. For a 2026 growth strategy, you need to aggregate data from three primary silos:
- Communications: Exporting Gmail threads and Slack history provides the "why" behind past decisions.
- Financials: CSV exports from Stripe or your accounting software allow the AI to correlate marketing spend with actual revenue growth.
- Creative Assets: Historical brand books, successful ad copy from Google Ads, and performance data from platforms like Stormy AI for creator partnerships.
Once collected, the data must be chunked. You cannot embed a 200-page PDF as a single point. You must break it into smaller, overlapping segments so the semantic search can be surgical in what it retrieves.
"If you did nothing but take all of your emails you've ever written and gave them to a vector store, the timeline and strategic insights it could generate would be shocking."
Step 2: Choosing Your Architecture (Custom GPT vs. API)
Depending on your technical resources, there are two paths to building your proprietary brain in 2026:
The 'No-Code' Path: Custom GPTs and Projects
Platforms like OpenAI and Claude allow you to create "Projects" or "Custom GPTs" where you can upload up to 100 files. Behind the scenes, these platforms are building a mini-vector store for you. This is ideal for small marketing teams looking to analyze a specific campaign or a single year's worth of data.
The 'Pro' Path: API-Driven Vector Databases
For a true 2026 growth strategy, you want a persistent knowledge base. This involves connecting your data to a vector database (like Pinecone or Milvus) via an API. You then use a framework like LangChain to connect your vector store to ChatGPT. This allows for infinite data scaling and real-time updates from your CRM and project management tools like Monday.com or Asana.
Privacy and Trust: The 2026 Security Mandate
Why running AI models locally can help protect your sensitive business data.Giving an AI access to your entire Gmail or Slack history is a massive leap of faith. In 2026, the primary hurdle isn't the technology; it's the access control. Most third-party integrations require "all or nothing" access to your email, meaning the AI sees your private family messages alongside your business strategy.
To mitigate this, growth-focused companies are opting for local-first AI processing or enterprise-grade environments where data is never used to train the base model. When building your internal app, ensure you are using the API versions of these tools, as they typically offer stricter data privacy guarantees than the consumer-facing chat interfaces.
2026 Case Study: The AI-Generated Strategy Guide
Imagine a mid-sized e-commerce brand that has been operating since 2020. They have six years of emails, thousands of influencer contracts, and hundreds of campaign reports. By training a custom ChatGPT instance on this data, they were able to:
- Identify 'Ghost' Strategies: The AI found a specific influencer outreach tactic from 2022 that had a 400% ROI but was forgotten during a team turnover.
- Automated Onboarding: New marketing hires now have an "AI Buddy" they can ask, "Why do we prefer TikTok over Instagram for our 'vibe-check' campaigns?", and get an answer based on five years of meeting notes.
- Creator Sourcing: By integrating their historical performance data with discovery tools like Stormy AI, they could automatically find new influencers who matched the exact persona of their most successful past partners.
"The manager of the future is an 'agentic manager' who knows how to recruit, train, and give performance reviews to both humans and digital AI teammates."
The Next Step: From Teammate to Agent
Explore the future of digital teammates and AI agents in every company.As we move through 2026, the goal is shifting from Synthesis (summarizing data) to Orchestration. Tools like Agent.ai are already allowing businesses to set high-level goals—like "Increase our market share in the sustainable tech niche"—and letting the AI manage a fleet of sub-agents to execute the research, outreach, and analysis.
But these agents are only as good as the "backroom" access you give them. Just like you wouldn't expect a human hire to succeed without a login to your analytics and a seat at the strategy table, you cannot expect AI to drive growth if it's walled off from your private data.
Conclusion: Your AI is You to the Power of N
Training ChatGPT on your private data isn't about replacing your marketing team; it's about giving every team member an "Intern with a PhD" who has perfect memory of every decision the company has ever made. By implementing RAG and vector embeddings, you transform a generic chatbot into a proprietary growth engine.
The competitive moat of 2026 is built on context. Start by cleaning your data, choosing a secure vector store, and treating your AI as a teammate that needs to be onboarded. The companies that win will be those that realize AI is not a replacement for creativity—it is the ultimate amplifier of it.