
Building a profitable online directory is often seen as a relic of the early 2000s, but for those who understand the data layer of the modern web, it remains one of the most resilient paths to generating passive income. The secret isn't in a flashy UI or complex features; it's in proprietary data enrichment. By combining high-volume web scraping for directories with Large Language Models (LLMs), you can create content that is objectively more useful than legacy competitors who rely on generic data feeds.
In this guide, we will break down the technical process of using a Google Maps data scraper to pull thousands of raw data points and then using AI to extract high-value insights from user reviews. This strategy allows you to rank for hyper-specific long-tail keywords that your competitors are completely ignoring, creating a significant SEO moat for your business.
Step 1: Finding High-Intent Niches with Ahrefs
Before you write a single line of code or fire up a scraper, you must validate that people are actually looking for curated information in your niche. The most effective strategy is to look for fragmented search intent. This occurs when users aren't just searching for a broad category, but are looking for specific attributes within that category.
Using a tool like Ahrefs, you can search for the modifier "near me" to identify local queries with massive volume. For instance, while "dog park" is a high-volume keyword, the real opportunity lies in the fragmentation: "indoor dog park," "off-leash dog park," and "dog water park." If people are searching for these specifics, it’s a signal that standard maps are failing to provide the right filters. Aim for niches with 30,000 to 100,000 monthly searches and a Keyword Difficulty (KD) under 20-30 for the best results, as noted in recent search intent research. However, experienced builders can target KD 50+ if they have a superior data enrichment strategy.
Step 2: Scraping Google Maps Data Without Getting Blocked
Once you’ve identified your niche, you need to acquire the raw data. The goal is to get a comprehensive list of every relevant business or location nationwide. Attempting to build your own scraper for Google Maps is a fool's errand for most, as the platform has sophisticated anti-scraping measures. Instead, professional builders use a dedicated Google Maps data scraper like Outscraper.
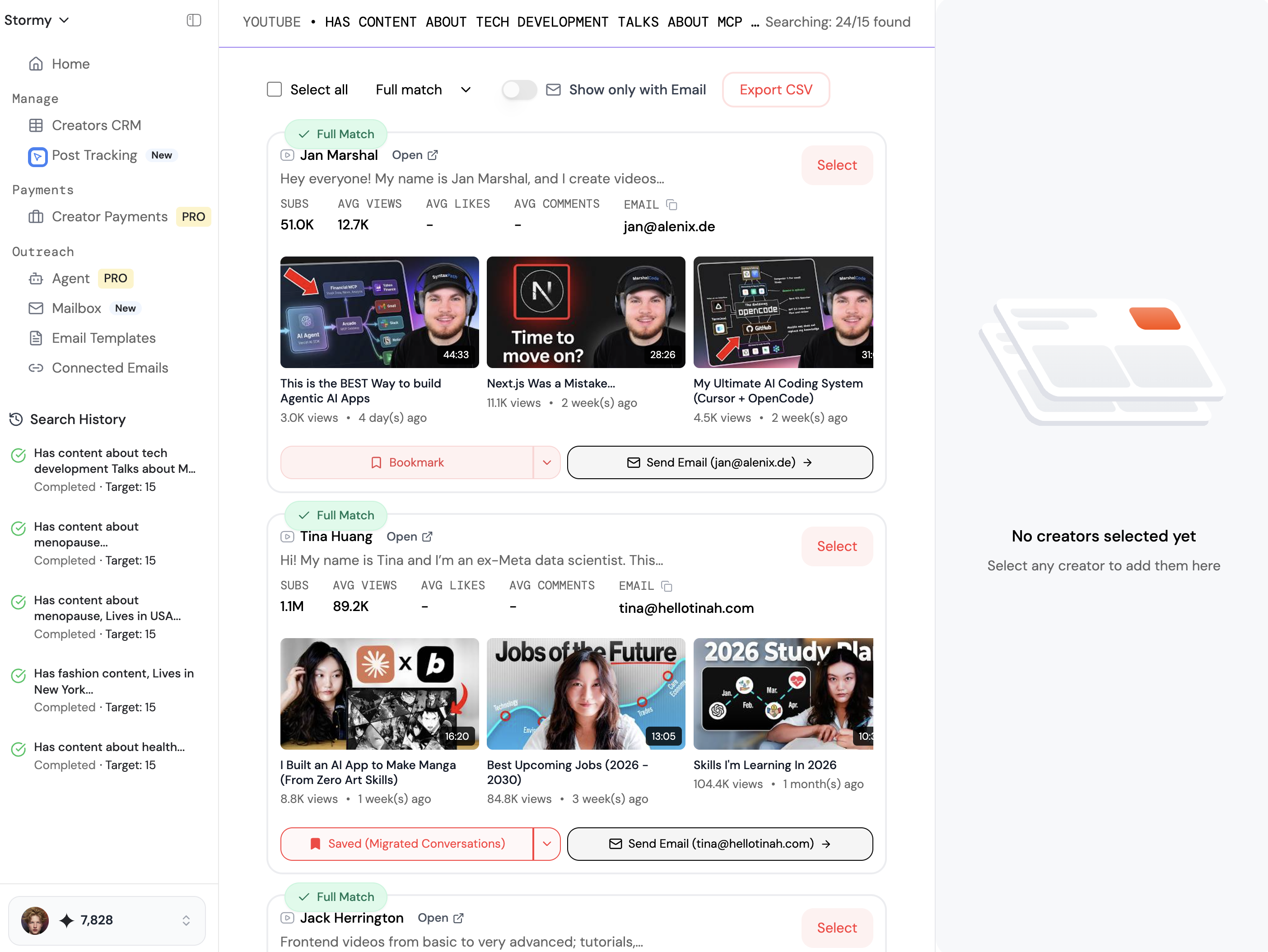
When setting up your scrape, the most critical step is to target specific Google Categories rather than plain text queries. For example, if you are building a dog park directory, selecting the exact category "Dog Park" ensures a much higher data quality than searching for the phrase. This reduces the amount of "junk data" (like pet stores or vet clinics) that ends up in your final export. Key parameters you should always include in your scrape are:
- Business Name and Address: The foundation of any listing.
- Review Count and Rating: To filter for quality.
- Location Link (CID): Essential for future AI enrichment.
- Working Hours and Phone Numbers: To provide basic utility to the user.
A nationwide scrape can yield anywhere from 5,000 to 120,000 rows of data. While this may seem overwhelming, it is the raw material needed to build a massive programmatic SEO project. Understanding the legal landscape of web scraping is also vital before scaling up.
Step 3: Cleaning 'Junk' Data: Manual vs. Automated Parsing
Scraping is messy. No matter how precise your categories are, you will inevitably end up with irrelevant listings. Cleaning 100k+ rows of data requires a two-step process: broad manual filtering followed by AI-assisted refinement.
First, use a spreadsheet tool like Google Sheets or Excel to perform "bulk deletes." Remove any rows that lack a physical address or have zero reviews. These are low-quality listings that will dilute your SEO value. Next, look for patterns in the junk. If you are scraping dog parks, you might see big-box retailers like Walmart appearing because they were mentioned in a review. You can quickly filter and delete these based on name patterns.
For the remaining data, ChatGPT or Claude can be used to parse smaller batches of data. By feeding the LLM a list of business names and descriptions, you can ask it to "Identify and flag any listings that are not specifically public parks for dogs." This hybrid approach ensures you don't "throw the baby out with the bathwater"—a common mistake when relying solely on automated scripts.
Step 4: AI Data Enrichment: Scanning Reviews for Hidden Amenities
This is where your directory goes from "basic" to "industry-leading." Most directories simply pull the name, address, and rating. To beat the giants, you must provide amenity-level data that isn't found in standard API feeds. This requires AI data enrichment.
People mention the most important features of a location in their reviews. For a dog park, users care about shade, water fountains, benches, and parking. To automate this, you can use a workflow that takes the Google Location ID, pulls the top 10-20 reviews, and passes them through an LLM with a specific prompt: "Based on these reviews, does this park have a water fountain? Answer True or False and provide a one-sentence summary."
This allows you to create new columns in your database for:
- Amenities: (e.g., Shade: Yes, Water: Yes, Fenced: No).
- Sentiment Summaries: A quick overview of what people love or hate.
- Unique Tags: (e.g., "Best for small dogs," "Usually crowded on weekends").
If you are managing high-volume data like this for an influencer or creator-focused directory, Stormy AI can be a massive help. While it is built for influencer discovery and vetting, its ability to analyze and summarize creator profiles at scale follows the same logic of turning raw data into actionable insights.
Step 5: Building the SEO Moat with Unique Data Points
Why go through all this trouble? Because unique data points act as an SEO moat. When Google crawls your site and sees that you have categorized 5,000 dog parks by "shade availability," and your competitors haven't, you become the most relevant result for the search "dog parks with shade in Los Angeles."
This is the essence of programmatic SEO. You aren't just creating one page; you are creating thousands of permutations of location + amenity. Legacy sites like Yelp or BringFido are often too broad to capture these niche clusters. By focusing on deep enrichment, you provide a better user experience, which leads to higher dwell times and better rankings.
Furthermore, this data is incredibly valuable for monetization. Once you have a highly-trafficked directory with unique data, you can funnel that traffic into several streams:
- Display Ads: Use Google AdSense for passive revenue.
- Affiliate Play: Recommend relevant products (e.g., dog travel gear) based on the location's features via platforms like Shopify.
- SaaS Layer: Build software tools on top of your data to help business owners manage their reputation.
Step 6: Implementing Static Pillar Pages vs. Programmatic Builds
For those just starting out, you don't necessarily need a complex custom-coded site. A "static pillar page" directory built on WordPress or Framer can work exceptionally well. The strategy involves creating long, comprehensive pages for major cities (e.g., "Best Dog Parks in Long Beach") that list all your enriched data points in a single, high-authority view.
These pages rank for hundreds of city-specific keywords because they are information-dense. Ensure your site structure includes a clear table of contents, internal links between state and city pages, and embedded maps using the Google Maps Platform. This architecture signals to search engines that your site is a comprehensive topical authority on the subject.
Conclusion: The Future of Directories is AI-Powered
The barrier to entry for building a directory has never been lower, but the barrier to ranking a directory is higher than ever. To succeed, you must move beyond the basics of name and address. By leveraging web scraping for directories and AI data enrichment, you can transform raw Google Maps data into a high-value asset that serves both users and search engines.
Remember, the goal is to provide curation that saves the user time. If your directory can tell a user which park has the best shade and the fewest crowds, you've won. Whether you are building a directory for dog parks, tech startups, or sourcing UGC creators, the principles remain the same: find the data, clean it, enrich it with AI, and build a moat that your competitors can't touch. Start small, validate your niche, and let the data do the heavy lifting for you.