Mastering Claude Code FinOps: How Growth Teams Can Scale AI Output Without Unpredictable Bills
Learn how growth teams manage FinOps for AI agents, using predictive billing and context management to scale Claude Code development while slashing costs by 94%.
In early 2026, the promise of AI-driven growth has shifted from simple chatbots to autonomous agentic workflows. For growth teams, this means scaling feature velocity at a pace previously impossible. However, this new era of "agentic planning" has introduced a significant operational hurdle: the unpredictable explosion of API token costs. Engineering leaders are now facing the reality that an unoptimized power user of tools like Anthropic’s Claude Code can easily burn through $400 per week in tokens alone.
As the global AI coding assistant market surges toward $8.5 billion in 2026, according to market analysts, the focus is shifting from adoption to efficiency. With 84% of developers now utilizing AI tools daily (as noted in the Stack Overflow 2025 Survey), growth leads must implement a robust FinOps for AI agents framework. This article provides the playbook for scaling AI output while bringing that $400/week burn down to a sustainable $15/week.
The Rise of FinOps for AI: Why 2026 Budgets Are Shifting
In previous years, AI tooling was often treated as a flat-rate subscription expense. In 2026, the model has shifted. While Cursor and GitHub Copilot maintain massive ARR leads, the emergence of terminal-based agents like Claude Code has introduced variable API costs that can derail a department's budget in days. Engineering leaders are now earmarking between $1,000 and $3,000 per developer annually specifically for AI tooling, a sharp increase from previous levels, according to research from DX - Engineering Enablement.
"The ROI of agentic coding is undeniable—a 4,868x return compared to manual senior developer hours—but without cost visibility, it’s a runaway train."
The core issue is that agentic tools execute multi-file refactors autonomously. Without FinOps for AI agents, a single complex prompt can cost upwards of $20. A power user on the Claude Max plan might discover they are consuming $336 of tokens in just six days, as reported by users on Reddit. To counter this, growth teams are adopting "Predictive Billing" and "Context Tiering" to maintain high feature velocity without the financial shock.
Predictive Billing: Stopping the $25 Prompt Before It Happens
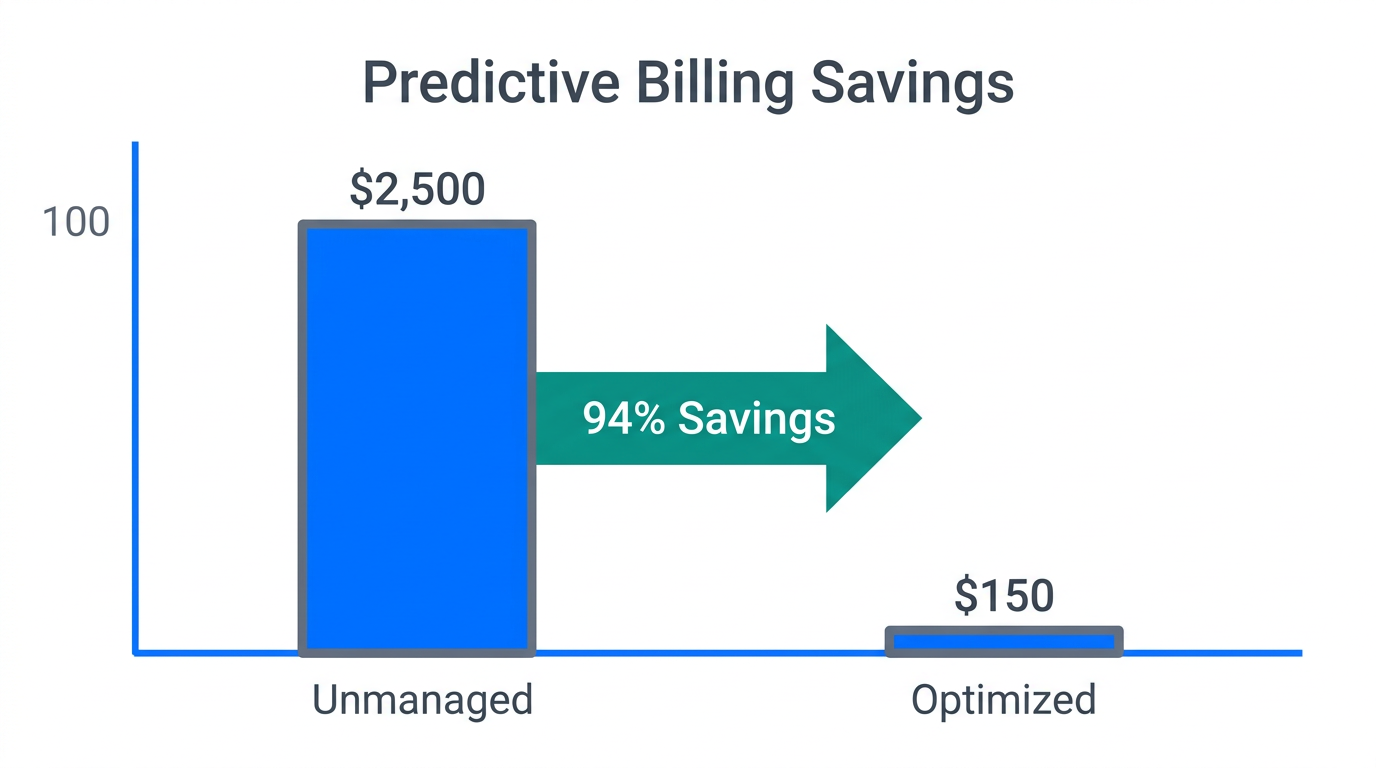
One of the primary frustrations with Claude Code and similar CLI agents is the zero-visibility problem. By default, the tool provides no cost estimate before a prompt runs. To solve this, growth teams are integrating Tarmac-Cost into their developer environments. This tool intercepts prompts and uses conformal prediction to provide a cost range before execution. According to data from the Tarmac GitHub repository, this method achieves 81% accuracy in predicting task costs based on real-world samples.
By using predictive billing, developers can decide if a specific refactor is worth a $15 token spend or if it should be broken down into smaller, more manageable sub-tasks. This level of enterprise AI cost control is essential for growth teams that need to justify every dollar of operational spend. This transparency allows leads to set hard caps per developer, preventing the "surprise" $1,600 monthly bills that plagued early adopters.
| Optimization Tool | Primary Function | Estimated Savings |
|---|---|---|
| Tarmac-Cost | Pre-run cost estimation | 30-40% by preventing over-scoped prompts |
| Cortex-TMS | HOT/WARM/COLD file tiering | 94.5% reduction in session costs |
| LiteLLM | Proxy for monitoring & capping | Varies based on set hard limits |
Context Management as a Growth Lever: Slashing Costs by 94%
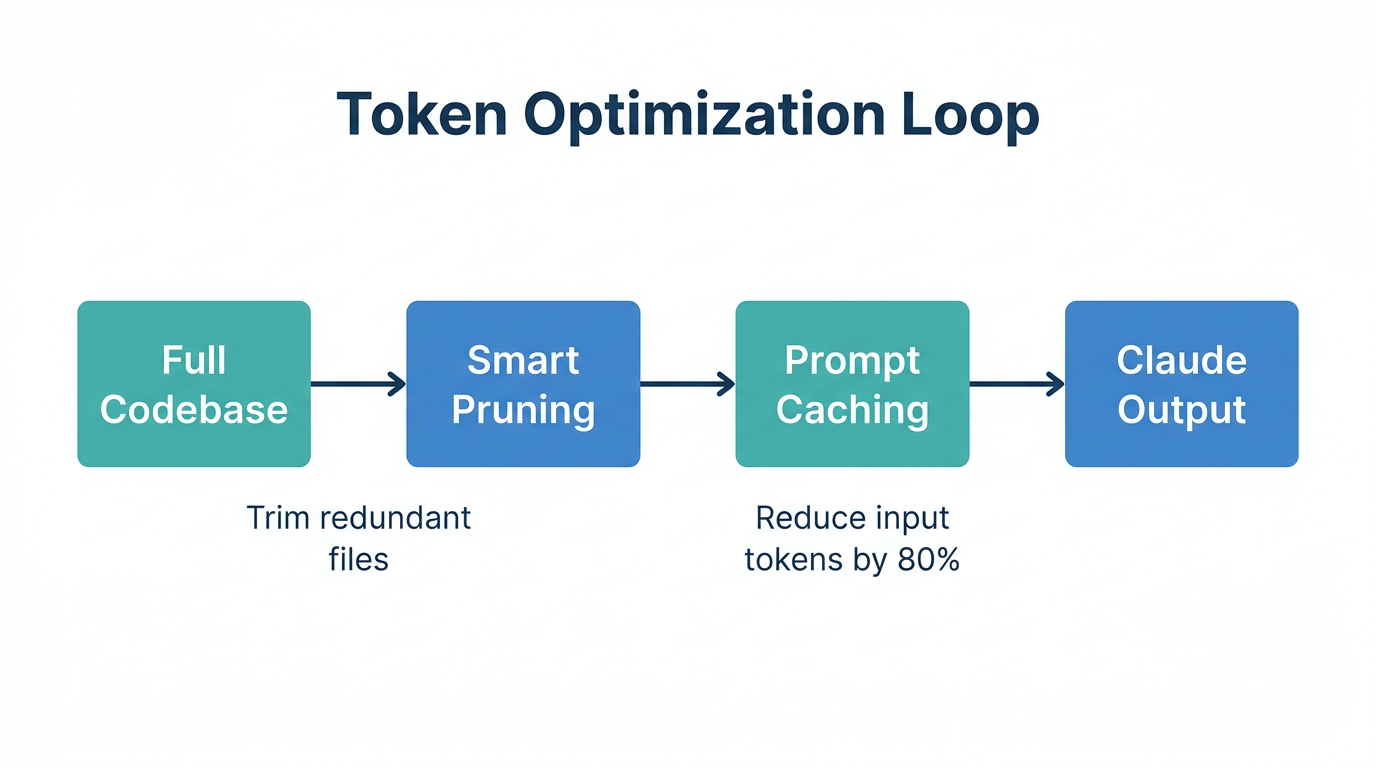
In 2026, the availability of 1-million-token context windows, as announced on the Anthropic Blog, is both a blessing and a curse. While it allows for massive code ingestion, it often leads to "Context Bloat." Developers frequently forget to run the /clear command, leading them to carry 100k tokens of stale history into every new prompt. This is the #1 cause of the $400/week burn rate.
To combat this, teams are utilizing Cortex-TMS (Context Tiering System). This system organizes a codebase into three tiers:
- HOT: Only the files directly related to the active task (approx. 3.6k tokens).
- WARM: Recent patterns and documentation (10k tokens).
- COLD: Archives and old sprints (50k+ tokens).
By only loading "HOT" files by default, developers have reported a 94.5% reduction in session costs, bringing the cost per session from $0.11 down to $0.01, according to discussions in the Claude Code community. This discipline ensures that growth teams are only paying for the context that actually contributes to the current feature build.
"The 'Context Bloat' tax is the hidden killer of AI budgets. Mastering the /compact command is no longer optional—it's a financial requirement."
Strategic Model Mapping: Assigning the Right Tool to the Right Task

Not every coding task requires the maximum reasoning power of Claude 3.7 Sonnet or Opus. Growth teams are now practicing Strategic Model Mapping, a core pillar of scaling AI development teams. This involves using the /model command to switch between different intelligence tiers based on the complexity of the task.
As revealed in case studies from power users, a hybrid habit often yields the best balance. For routine boilerplate, unit tests, or documentation, the Haiku 4.5 model is more than sufficient. Sonnet 4.6 is reserved for 90% of standard refactoring and feature development, while Opus 4.6 is kept strictly for architectural brainstorms. This strategy prevents "thinking tokens" from ballooning on simple tasks, especially when using Claude 3.7's "Extended Thinking" mode, which can sometimes over-engineer solutions, as noted by critics at 16x.engineer.
Just as growth teams optimize their engineering stack, they must also optimize their marketing operations. While developers focus on token efficiency, marketing leads use platforms like Stormy AI to automate the discovery and outreach of UGC creators. By leveraging AI-powered search across TikTok and YouTube, teams can ensure their creator marketing spend is as calculated and high-ROI as their coding workflows.
The Claude Code Optimization Playbook: 5 Steps to $15/Week
To reach the target of $15 per week while maintaining peak output, follow this sequential playbook designed for high-growth engineering teams.
Step 1: Shift to Subscription Over API
While the API offers granular control, heavy users should move to the $100 or $200 Claude Max Plan. As analyzed by IntuitionLabs, these plans cap the costs of "unlimited" usage that would otherwise exceed $1,600 on the pay-as-you-go API. It turns a volatile expense into a predictable line item.
Step 2: Start in Plan Mode
Always initiate complex tasks in Read-Only Plan Mode (Shift+Tab). Boris Cherny, a pioneer in agentic workflows, recommends this "Explore-Plan-Execute" workflow. This forces the AI to use a cheaper sub-agent to explore the codebase before committing to expensive implemention cycles.
Step 3: Implement Tiered Context
Use Cortex-TMS to ensure Claude isn't reading your entire node_modules or git history with every prompt. Keeping your CLAUDE.md under 100 lines and modularizing project standards into separate files ensures you only pay for relevant tokens.
Step 4: Use the /compact Command Frequently
When your session reaches 70% capacity, run /compact. This summarizes the history while preserving essential project instructions, effectively resetting the "input tax" on every subsequent message in that session.
Step 5: Leverage "Off-Peak" Limits
In a tactical move to manage compute capacity, Anthropic recently doubled usage limits during off-peak hours (weekends and weekdays outside 8 am–2 pm ET), as reported by Abhs.in. Move heavy architectural refactors to these windows to maximize your subscription value.
Conclusion: Balancing Speed and Sustainability
The transition to agentic AI tools like Claude Code represents the most significant shift in developer productivity since the invention of the IDE. When managed correctly, the ROI is staggering—Faros AI, for instance, used AI agents to refactor over 200 files and significantly reduce Docker image sizes in just a few hours.
However, the scaling of AI development teams requires more than just access to the latest models; it requires FinOps discipline. By utilizing predictive billing through Tarmac-Cost, managing context via Cortex-TMS, and strategically mapping models, growth teams can eliminate the "Context Bloat" tax. Just as growth leads rely on Stormy AI to manage creator relationships and scale UGC content without manual overhead, they must now apply that same automation mindset to their AI token budgets. In 2026, the teams that win will not be those with the largest budgets, but those with the most efficient AI operations.