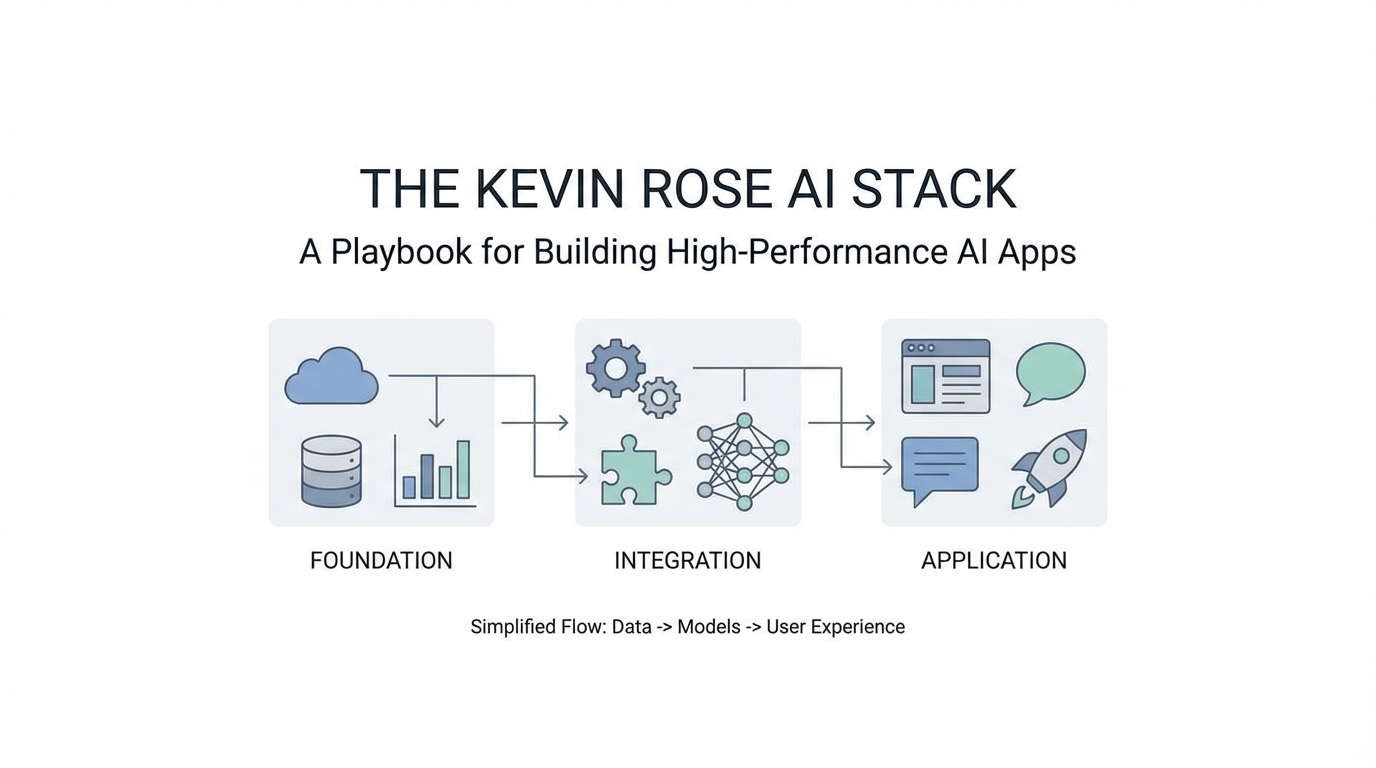
When legendary entrepreneur Kevin Rose—the mind behind Digg and a leading partner at True Ventures—shares his internal development workflow, the tech community listens. In a recent technical breakdown, Rose unveiled a project internally named "Nylon," an AI-powered news aggregator designed to outperform legacy systems by identifying high-value signals in a sea of digital noise. Building a modern AI tech stack is no longer just about calling an API; it is about creating a resilient infrastructure that handles non-deterministic outputs, manages complex background jobs, and maintains data integrity across multiple LLM providers.
The Foundation of Durability: Trigger.dev and Background Workflows
One of the most common pitfalls when building AI products is the reliance on standard edge functions or simple cron jobs for complex tasks. AI workflows—such as summarizing articles, generating embeddings, or crawling web pages—are notoriously prone to timeouts and rate limits. Rose solves this by implementing Trigger.dev, an open-source framework for building reliable background jobs in TypeScript.
Rose uses Trigger.dev to manage what he calls an "expansion orchestrator." When a new piece of content enters the system via RSS, it isn't just stored; it triggers a chain of events. Trigger.dev ensures durability by providing automatic retries and state management. If a model provider like OpenAI experiences a 503 error or a scraper gets temporarily blocked, the system doesn't crash. Instead, it enters a retry loop, ensuring that every article eventually reaches the enrichment stage.
For developers, this means you can write complex, long-running logic without worrying about the execution environment timing out. Rose notes that he runs thousands of these tasks daily for less than $100 a month, highlighting the efficiency of offloading AI tech stack logic to specialized orchestration layers. By utilizing these tools, even a solo engineer can manage a data pipeline that would have previously required a dedicated DevOps team.
The Abstraction Layer: Swapping Models with Vercel AI Gateway
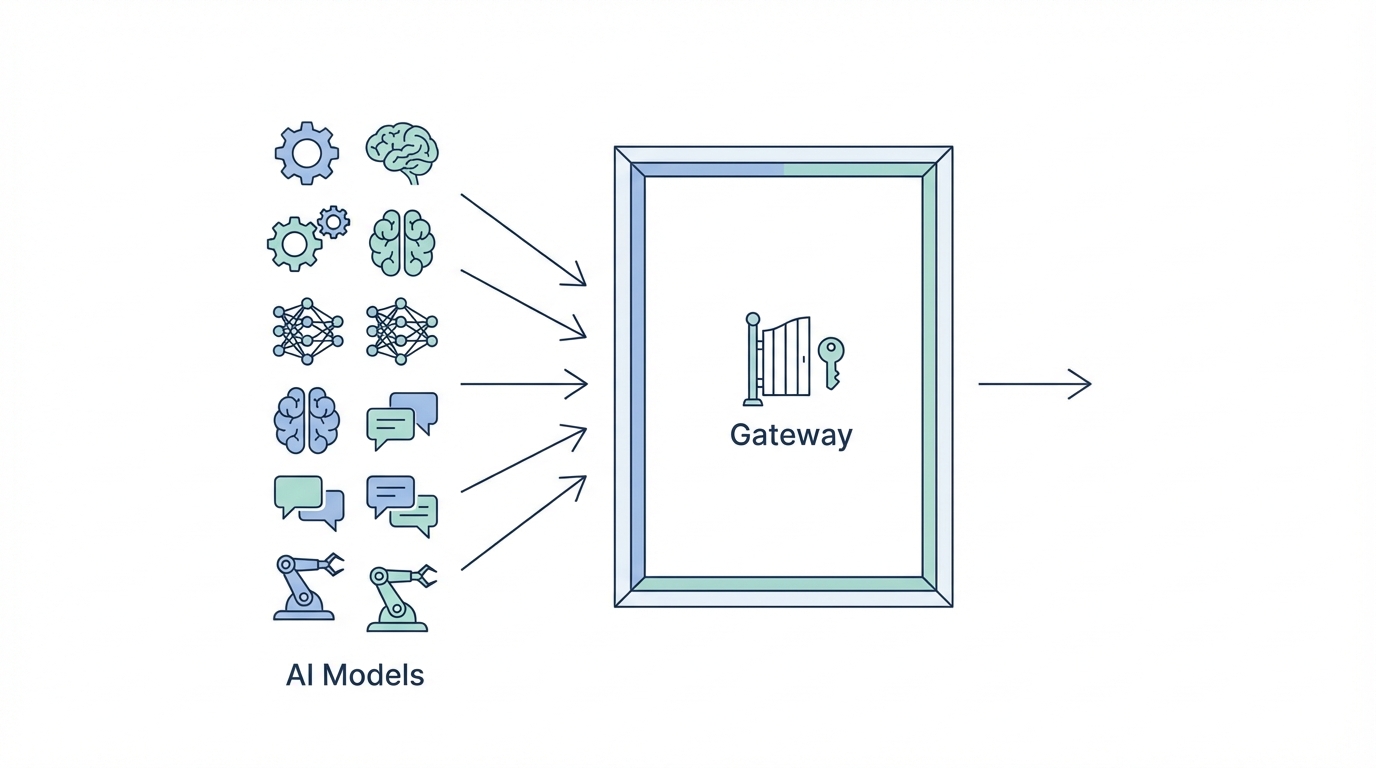
The AI landscape moves so quickly that hard-coding your application to a single model provider is a technical debt trap. Kevin Rose advocates for using the Vercel AI Gateway to maintain maximum flexibility. This tool acts as a unified interface that allows developers to swap between LLM providers like Claude, OpenAI, and Gemini with a single line of code.
In the "Nylon" project, Rose utilizes different models for different strengths. While he uses GPT-4o mini for cheap, fast summarization, he might flip a switch to use Claude for more nuanced linguistic analysis. The Vercel AI Gateway provides a centralized dashboard to monitor usage, set up caching to reduce costs, and implement failover logic. If one provider goes down, the gateway can automatically route requests to another, maintaining 100% uptime for the user-facing application.
This approach is essential for modern building AI products. It prevents vendor lock-in and allows developers to optimize for both cost and performance on the fly. As models become commoditized, the ability to jump to the most efficient provider (the "vibe coding" approach) becomes a massive competitive advantage for early-stage startups and solo builders alike.
Data Ingestion and the Gemini Search Fallback
A major challenge in high-performance AI apps is obtaining high-quality ground truth data. Rose's workflow involves multi-stage ingestion using Iframely for rich metadata and Firecrawl for deep web scraping. However, even the best scrapers can be blocked by sites like Reddit or high-security news outlets.
To combat this, Rose implements a "judge" system. If initial scraping attempts return low-quality signals or 403 errors, the system triggers a Gemini fallback. By leveraging Gemini's built-in search and grounding capabilities, the stack can effectively "ask" Google's model to find and verify the core content of an article. This ensures that the system always has a "winner" for the content field, even when traditional scraping methods fail.
This Trigger.dev tutorial logic is vital: the system compares the outputs from RSS, Iframely, Firecrawl, and Gemini, then assigns a "winner" based on character count, keyword density, and formatting quality. This ensures that the downstream vector embeddings are built on the cleanest data possible, preventing the "garbage in, garbage out" problem that plagues many AI aggregators.
The Mathematical Brain: Postgres with pgvector
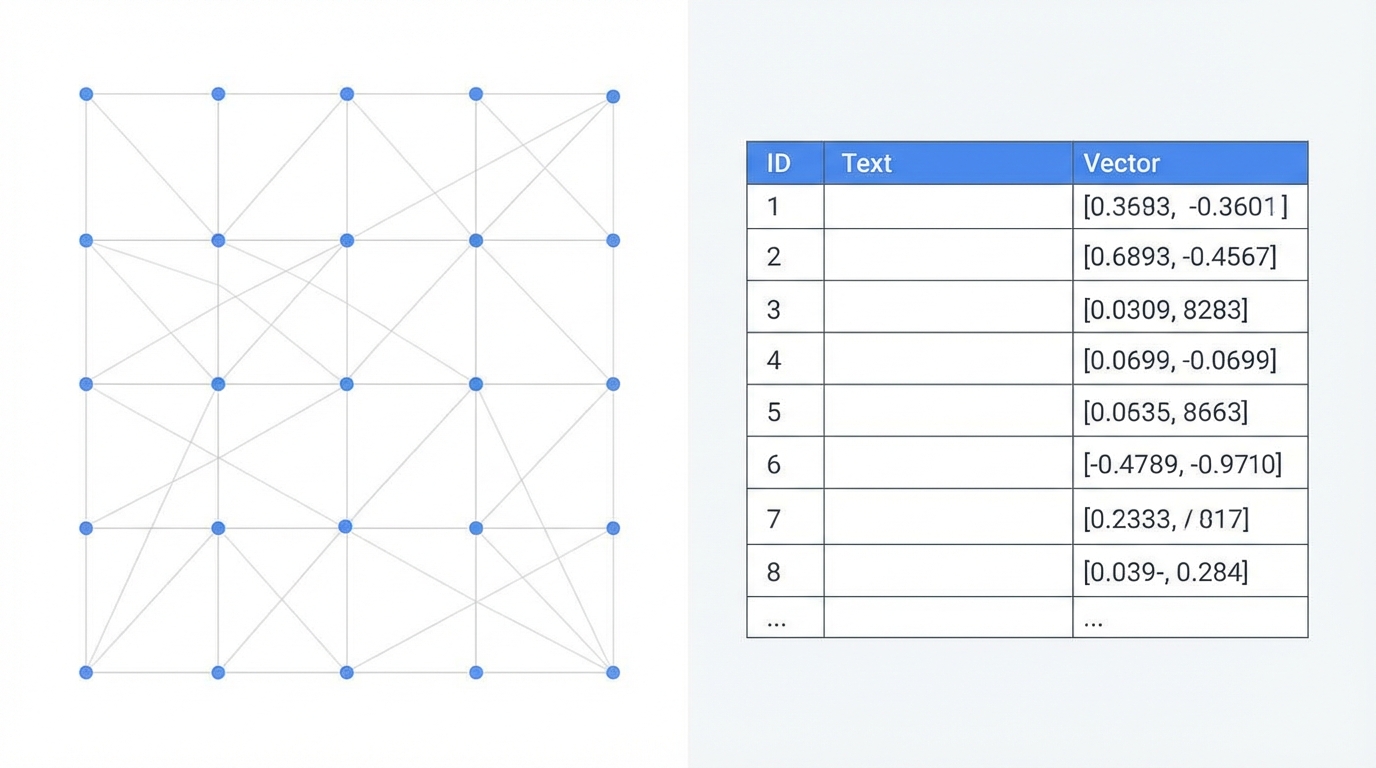
At the heart of any AI-powered discovery tool is a vector embeddings database. Rather than using specialized, expensive standalone vector databases, Kevin Rose relies on a tried-and-true solution: Postgres with the pgvector extension. This allows developers to store mathematical representations of data directly alongside traditional relational data.
The power of vector embeddings lies in their ability to understand semantic meaning rather than just keyword matching. Rose explains that while old-school search engines would struggle to distinguish between "Apple sues Google" and "Google sues Apple" (since they share the same keywords), a vector-based system understands the nuanced linguistic difference between the two. This is critical for clustering news stories and identifying original source material.
In the Nylon stack, every article is transformed into a high-dimensional vector using OpenAI's embedding models. These are stored in a Postgres pgvector column. When new articles arrive, the system calculates the cosine distance between them to automatically group them into clusters. This allows Rose to see which stories are gaining the most "gravity" across 60+ different sources in real-time.
The Playbook: Building Your Own Expansion Orchestrator
Ready to build? Follow this step-by-step guide to implementing a high-performance AI ingestion and expansion pipeline similar to the one Kevin Rose uses for Nylon.
Step 1: Ingest the Raw Signal
Connect your data sources—whether they are RSS feeds, social media APIs, or custom scrapers—to a unified ingestion function. Use Google Search alerts or specialized APIs like Tavily to find related content that exists outside your primary feeds.
Step 2: Initialize the Background Task
Send the raw URL to a Trigger.dev task. This task will manage the lifecycle of the data, including metadata extraction and model calls. This ensures that if the model provider is slow or fails, your main application thread remains unblocked and responsive.
Step 3: Multi-Source Enrichment
Run three parallel requests: one to Iframely for the card metadata, one to Firecrawl for the markdown content, and one as a fallback to Gemini. Use a judge function to evaluate which source provided the cleanest, most comprehensive text.
Step 4: Generate Semantic Vectors
Pass the "winning" content to an embedding model via the Vercel AI Gateway. Store the resulting vector in your vector embeddings database (Postgres + pgvector). This is where tools like Stormy AI provide value for marketers, as they use similar AI discovery engines to source and manage UGC creators by analyzing their content quality and semantic relevance at scale.
Step 5: Apply Clustering and Scoring
Run a clustering algorithm (like DBScan or K-Means) on your Postgres data to group similar articles. Once clustered, apply a "Gravity Engine" score based on the number of sources reporting, the reputation of the authors, and the novelty of the topic. This identifies the "blockbuster" signals that require immediate attention.
The Product Mindset: Signal Over Noise
Building with this stack allows for a new era of "personal software." Rose emphasizes that success doesn't always mean millions of users; it means building a tool that provides utility for a specific audience. For example, by tracking which influential voices—like Marc Andreessen or Alexis Ohanian—are interacting with a specific story, you can assign an "editorial vote" that helps users ignore PR fluff and focus on technical breakthroughs.
For brands and growth marketers, managing these types of high-value signals is essential. Utilizing a creator CRM to track which influencers are driving conversations is the next logical step. While Rose builds for news, platforms like Stormy AI allow businesses to use AI search and discovery to find the right creators based on these same semantic signals, ensuring that outreach is hyper-personalized and automated.
Conclusion: The Future of AI Development
The Kevin Rose AI stack is a blueprint for durability and flexibility. By combining Trigger.dev for orchestration, Vercel AI Gateway for model management, and pgvector for semantic intelligence, developers can move beyond "slop" and build truly high-performance AI products. Whether you are building a news aggregator, a research tool, or an influencer discovery platform, the focus must remain on high-quality data ingestion and resilient background processing. Start building your own orchestrator today and focus on finding the signal in the noise.