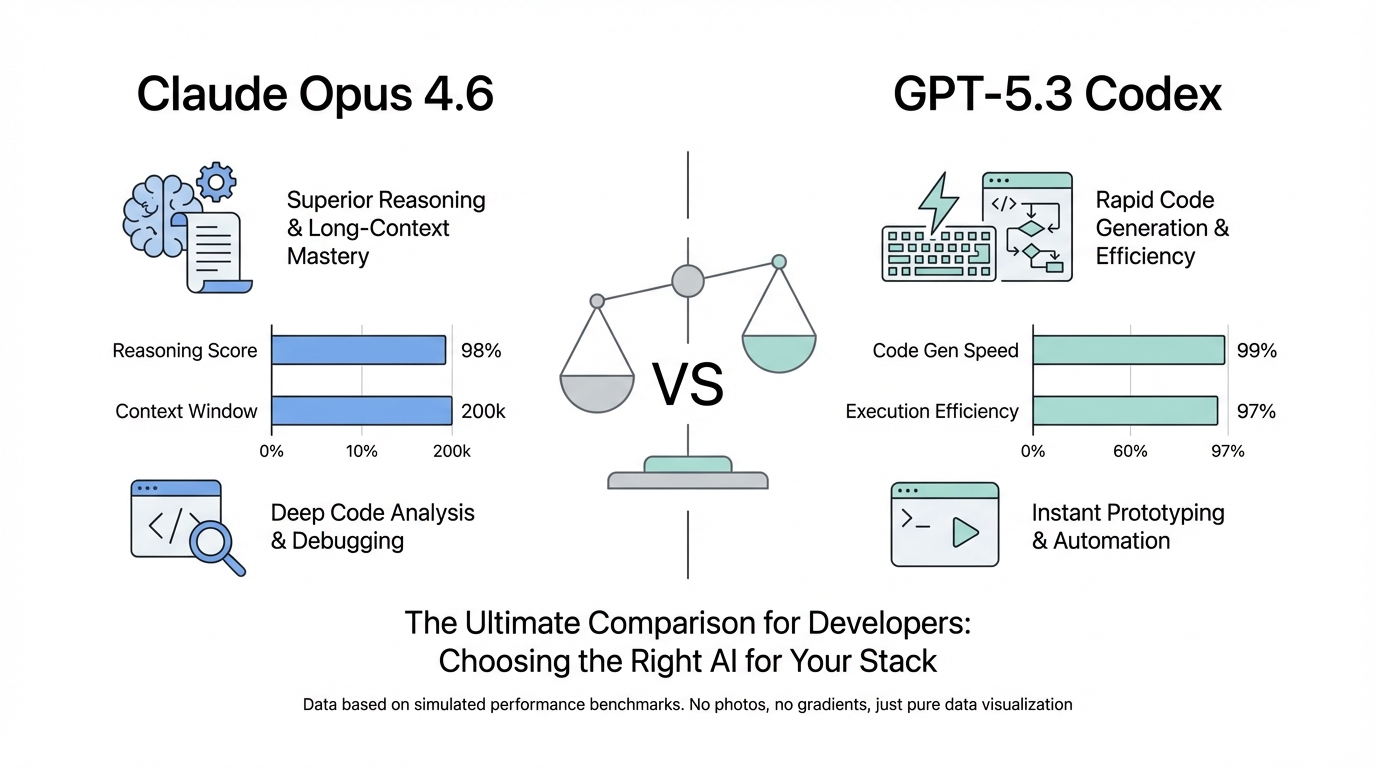
The landscape of software engineering shifted fundamentally today with a dual release that has set the developer community ablaze. Anthropic has officially launched Claude Opus 4.6, and in a characteristically rapid response, OpenAI unveiled GPT-5.3 Codex. This isn't just a battle of incremental updates; it is a clash of engineering philosophies. When choosing the best AI model for coding 2024, developers are no longer just looking at raw logic—they are choosing between two distinct methodologies: autonomous delegation and interactive collaboration. Whether you are a "vibe coder" or a staff engineer managing massive repositories, understanding the Claude Opus 4.6 vs GPT-5.3 Codex divide is essential for staying competitive in the era of the AI agentic workflow.
The Philosophical Split: Autonomous Delegation vs. Interactive Collaboration
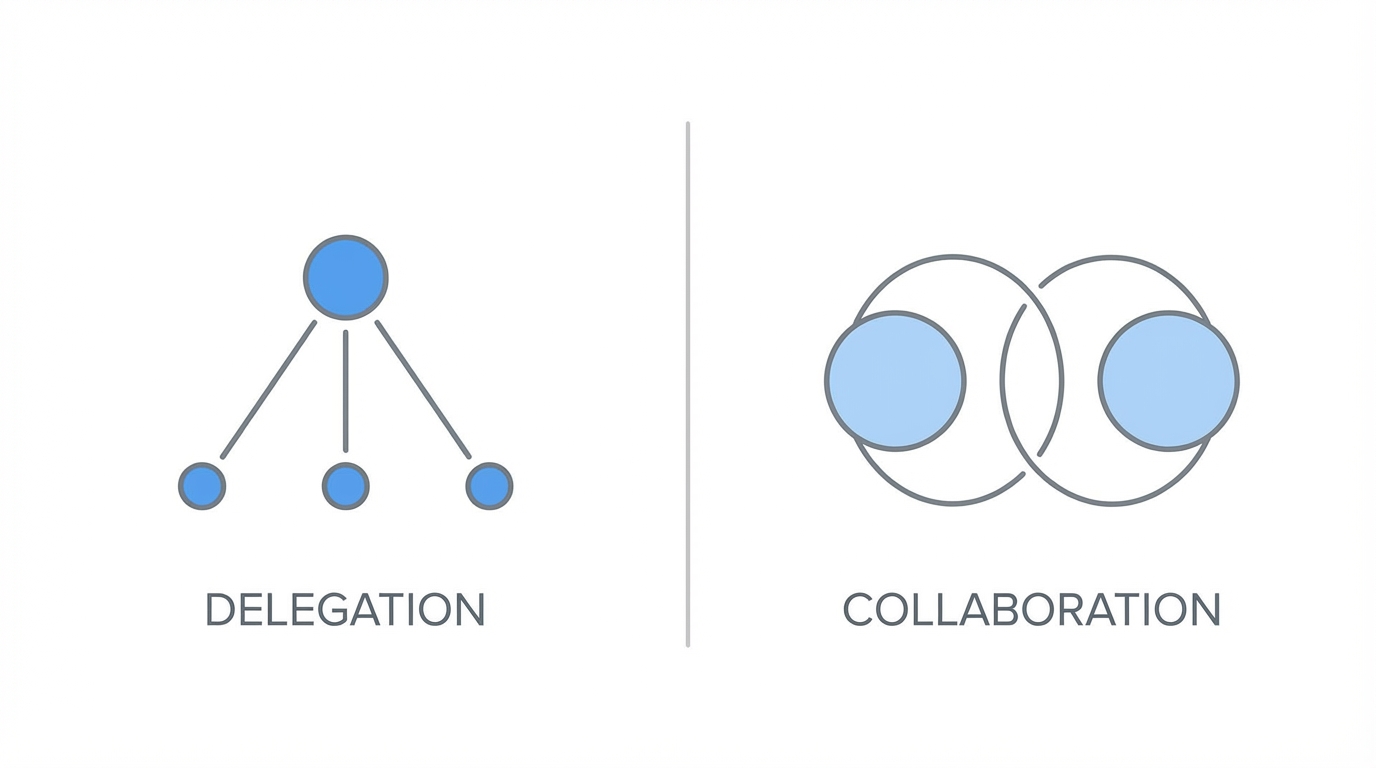
At the heart of the Anthropic vs OpenAI for developers debate is a widening gap in how these companies believe AI should fit into the development cycle. Claude Opus 4.6 is designed as an autonomous agent. It prioritizes deep planning, long-range reasoning, and minimized human interruption. It is built for the developer who wants to hand over a complex task—like refactoring a legacy module—and receive a completed, tested pull request an hour later.
Conversely, GPT-5.3 Codex leans into the human-in-the-loop (HITL) model. It functions as an elite pair programmer that thrives on mid-execution steering. OpenAI’s model is optimized for the developer who wants to stay in the driver's seat, catching hallucinations in real-time and adjusting the logic as the code flows. While Opus wants to be your Staff Engineer, Codex wants to be your Founding Engineer partner, moving fast and iterating alongside you.
Context Windows: The 1M Token Frontier vs. Optimized Memory
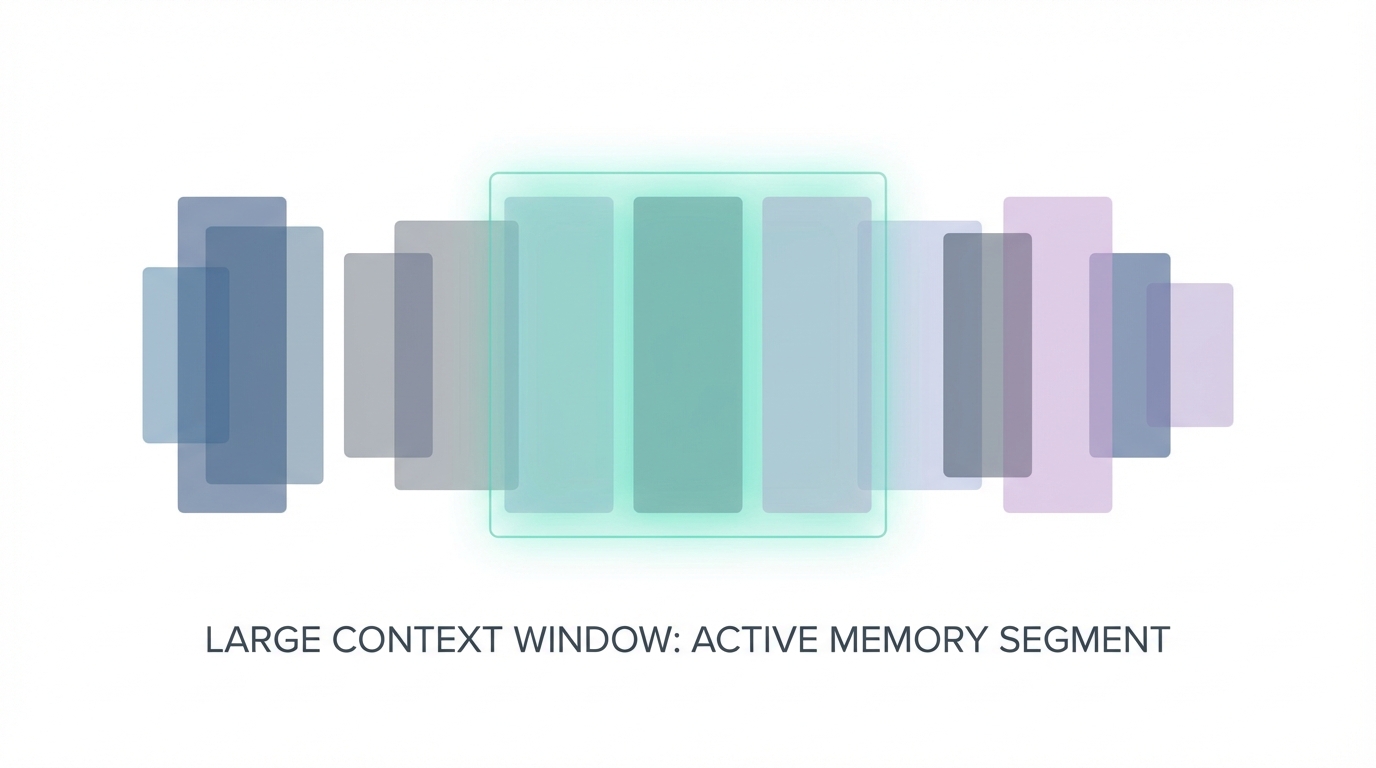
One of the most staggering differences in the LLM coding benchmarks for this generation is the handling of context. Claude Opus 4.6 boasts a massive 1-million-token context window. This allows it to ingest entire codebases, comprehensive documentation, and complex architectural diagrams simultaneously. This "total recall" capability makes it the superior choice for architectural sensitivity, as it can reason over the ripple effects a change in the auth layer might have on a distant microservice.
On the other side, GPT-5.3 Codex has opted for a more conservative 200,000-token window. While smaller, OpenAI argues that their model is optimized for progressive execution. Rather than trying to hold the entire universe in active memory, Codex uses advanced attention mechanisms to decide what to keep in working memory. This makes it significantly faster for end-to-end app generation but can occasionally lead to "flawed assumptions" if the necessary context was purged too early. For developers, the choice boils down to whether you need a model that reads the whole book before writing a page, or one that writes fast and learns as it goes.
Agentic Workflows: Multi-Agent Orchestration in Opus 4.6
The standout feature of Claude Opus 4.6 is undoubtedly Agent Teams. This experimental feature allows the model to spin up parallel sub-agents to tackle different aspects of a project simultaneously. In a recent test rebuilding a complex app like Polymarket, Opus was able to assign one agent to technical architecture, one to domain research (prediction markets), one to UX design, and one to QA testing.
To enable this in your local environment, you must update your settings.json file in the .claude directory. Adding the flag claude_code_experimental_agent_teams: 1 unlocks the ability for Claude to coordinate these sub-agents. While this is incredibly powerful, it is also token-hungry. A single architectural build can easily consume 200,000 to 500,000 tokens as the agents communicate and synthesize their findings. For those managing complex creator workflows or large-scale digital marketing campaigns, platforms like Stormy AI can help source and manage UGC creators at scale, providing a similar agentic efficiency to the marketing side of your business.
Benchmarking the Coding Champions: SWE-bench Pro and Terminal Bench
When looking at LLM coding benchmarks, the data shows a split victory. GPT-5.3 Codex currently leads the pack in SWE-bench Pro and Terminal Bench. Its ability to solve discrete, difficult engineering problems—often referred to as "correctness"—remains unparalleled. It is less likely to hesitate when requirements are ambiguous, choosing to ship code and let the user correct it.
However, Claude Opus 4.6 excels in Codebase Comprehension. It generates significantly more unit tests—often by a factor of 10x—compared to Codex. In a head-to-head build of a prediction market, Codex produced 10 passing tests, while Opus 4.6 produced 96. This "senior reviewer" personality makes Opus the safer bet for high-stakes enterprise environments where a "YOLO write code" approach is a liability.
Cost and Token Efficiency: Analyzing the High-Token Hunger
The power of the AI agentic workflow comes with a literal price tag. Because Claude Opus 4.6 relies on multi-agent orchestration, its token usage can be 5x to 10x higher than a standard interaction. Each sub-agent requires its own context and reasoning chain, meaning a simple prompt can quickly escalate into a million-token bill. While the Claude Code CLI makes this process seamless, developers must be mindful of their usage limits.
OpenAI’s GPT-5.3 Codex is generally more token-efficient for interactive tasks. Since it relies on the user to steer it, it doesn't spend as much "thinking time" (or Adaptive Thinking, as Anthropic calls it) exploring dead ends autonomously. However, for many, the cost of human time—waiting for a dev to review and fix mistakes—outweighs the cost of API credits. If you are building a startup and need to scale your outreach, using Stormy AI's influencer discovery can save hundreds of hours of manual search, mirroring the time-savings of an agentic developer workflow.
Personality Archetypes: The 'Staff Engineer' vs. the 'Founding Engineer'
Ultimately, the choice between Claude Opus 4.6 vs GPT-5.3 Codex comes down to the personality you want in your IDE. Claude Opus 4.6 is the Staff Engineer. It will overanalyze, it will hesitate if your requirements are vague, and it will ask, "Should we really do this?" before touching the production database. This is ideal for refactoring and maintaining large, complex systems like those managed by Bold Metrics, where precision is paramount.
GPT-5.3 Codex is the Founding Engineer. It asks, "How fast can I ship this?" It is overconfident, sometimes locking in flawed assumptions, but its speed allows for rapid prototyping that Opus can't match. If you are in the "vibe coding" stage of a project, Codex will likely feel more rewarding because of its immediate feedback loop and high-polish initial outputs.
Step-by-Step: How to Optimize Your Setup for Opus 4.6
To get the most out of the newest Anthropic model, follow this playbook for agentic coding:
Step 1: Update Your Environment
Ensure you are running the latest version of the CLI. Run npm update or claude update. You should see version 2.1.32 or higher. If you see a 1.x version, you are running the legacy engine and missing out on the 4.6 reasoning capabilities.
Step 2: Configure the Agent Teams
Navigate to your settings.json (usually located at ~/.claude/settings.json). You must manually enable the experimental features by adding: "claude_code_experimental_agent_teams": 1. This is what allows the model to handle multi-threaded research and execution.
Step 3: Utilize Adaptive Thinking
If you are using the API directly, leverage the Adaptive Thinking parameter. For complex architectural tasks, set the effort level to max. This tells Opus 4.6 to use its full reasoning depth without constraints, ensuring the highest quality of architectural sensitivity.
Conclusion: Choosing Your Path in the AI Era
There is no objective winner in the Claude Opus 4.6 vs GPT-5.3 Codex battle, but there is a clear winner for your specific workflow. If you value architectural integrity, massive context windows, and the ability to delegate entire modules to an autonomous team, Claude Opus 4.6 is the gold standard. It is the senior reviewer every large codebase needs.
If you prefer speed, interactive steering, and a model that pushes the boundaries of functional app generation, GPT-5.3 Codex remains the champion. Its performance on SWE-bench Pro proves it is still the king of getting things done quickly. As we move further into 2024, the most successful developers will likely be those who use both: Opus for the planning and architecture, and Codex for the rapid-fire iteration and shipping. Stop overthinking and start building—the tools have never been more powerful.