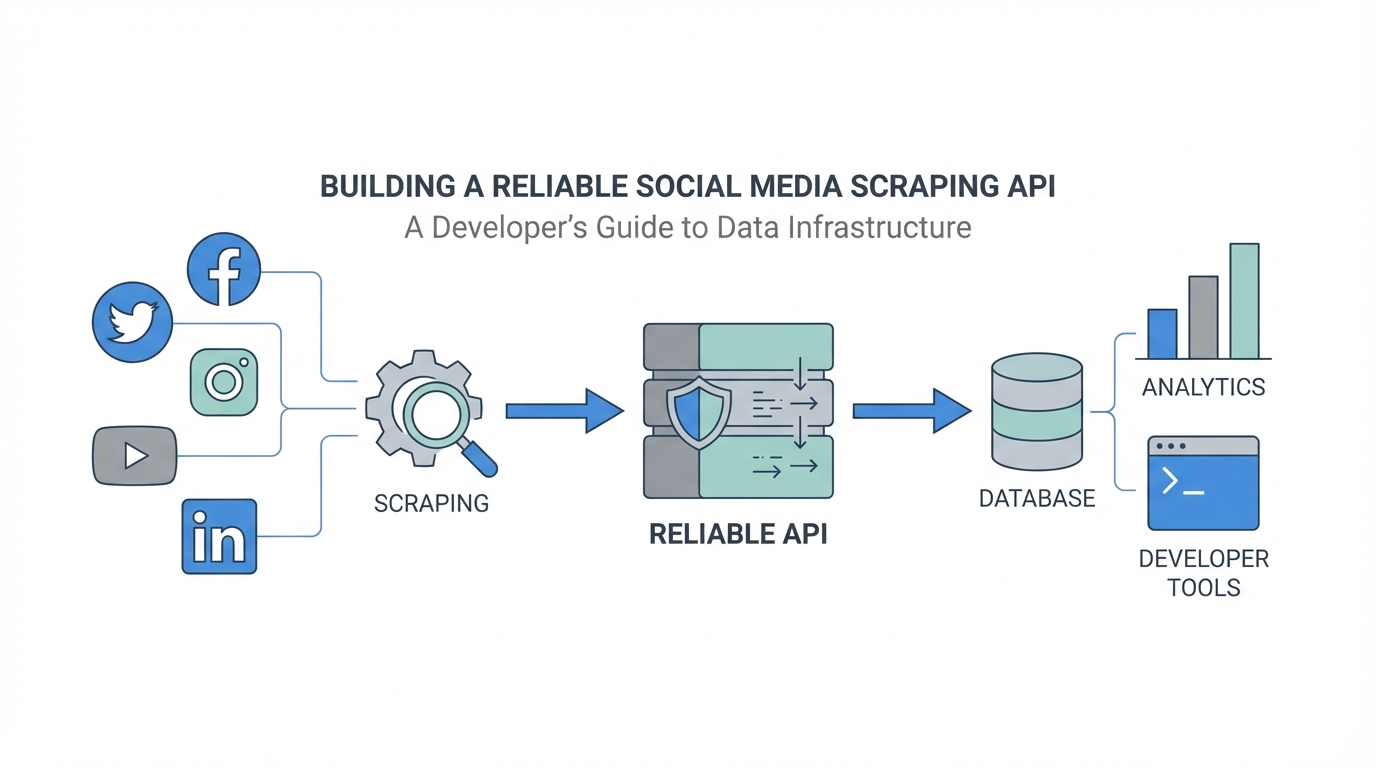
The tech industry often obsesses over original ideas, but the most successful SaaS developers know a secret: execution beats innovation every time. Building a robust social media scraping api isn't about reinventing the wheel; it's about building a better, more reliable bridge between raw public data and the brands that need it. In an era where influencer marketing and social commerce dominate, the demand for social media analytics infrastructure has never been higher. Developers who can reliably scrape instagram data, track YouTube engagement, and monitor TikTok trends are finding themselves at the center of a $20,000-per-month business model. This guide breaks down the exact infrastructure required to build, scale, and maintain a scraping service that handles millions of requests without breaking.
The Business Logic of Copying Success
Many developers spend months in the ideation phase, but as highlighted in recent discussions on platforms like Starter Story, sometimes the best business idea is one that is already working. If you see a scraping API listed on a marketplace like Acquire.com (formerly MicroAcquire) making $30,000 in monthly recurring revenue (MRR) with only 100 customers, it is a clear signal of market fit. The key is to take that proven model and improve it by 1%—whether through better reliability, faster support, or more intuitive documentation.
When you build a social media scraping api, you are solving a massive headache for other developers. Scraping is inherently fragile. Platforms like Instagram and TikTok change their internal structures frequently, and anti-bot measures are becoming increasingly sophisticated. By offering a reliable API, you are essentially selling 'peace of mind' to marketing agencies, link-in-bio tools, and influencer discovery platforms. For example, platforms like Stormy AI help brands find the right creators by leveraging these types of data pipelines to power their AI search engine across TikTok, Instagram, and YouTube, highlighting the real-world value of a stable scraping infrastructure.
Technical Stack Breakdown: Node.js and Beyond
A modern social media analytics infrastructure needs to be lightweight yet highly concurrent. For most developers, a node.js scraping tutorial-style approach using JavaScript is the most efficient path. Node.js is non-blocking and handles asynchronous HTTP requests exceptionally well, which is the bread and butter of web scraping. Using Node.js allows you to manage thousands of simultaneous requests without the overhead of thread-per-request models found in older languages.
The Core API Infrastructure
To build a production-ready API, you need a combination of hosting and database tools that can scale on demand. Most successful solo-run scraping APIs utilize a combination of Render for hosting the main API server and Supabase for managing the database. Render provides a seamless deployment pipeline, while Supabase offers a robust PostgreSQL backend with built-in authentication and real-time capabilities. For the frontend, using Astro combined with React provides a lightning-fast experience for users viewing documentation or managing their API keys.
Scaling with AWS Lambda
When you reach a scale of 20 million API requests per month, a single server won't cut it. This is where AWS Lambda becomes essential. By hosting individual scraping scripts on AWS Lambda, you can execute thousands of requests in parallel without worrying about server capacity. This serverless architecture ensures that if one platform’s scraping logic becomes slow due to heavy anti-bot measures, it won’t bottleneck the rest of your API. Leveraging an AI-powered code editor like Cursor can significantly speed up the development of these Lambda functions, allowing you to iterate on scraping logic in real-time.
Solving the 'Breakage' Problem: Proxy Rotation and Reliability
The biggest challenge in learning how to scrape instagram data isn't the code itself—it's staying under the radar. Social media platforms use sophisticated rate-limiting and fingerprinting to block scrapers. To solve this, proxy rotation for scraping is your most important tool. Without residential proxies, your API will be flagged and blocked within minutes.
The Role of Residential Proxies
Unlike data center proxies, which use IP addresses associated with servers, residential proxies use IPs assigned to actual homes. This makes the traffic look like it’s coming from a real user, making it much harder for platforms to block. To maintain a high success rate, you should rotate through multiple providers. Key players in this space include Evomi, which offers some of the most cost-effective residential proxies, Webshare for reliable data center and residential pools, and Massive for high-scale needs. Most developers spending $20,000 a month on their infrastructure find that proxy costs account for nearly 75% of their total expenses, often reaching $1,500 or more monthly.
Reliability also comes down to the framework you use for HTTP requests. While standard libraries like Axios work, specialized packages like impit (developed by Ampify) are often preferred in the scraping community because they are designed to handle the nuances of headers, cookies, and fingerprinting more effectively than generic tools.
Scaling to 20 Million Requests: Management and Monitoring
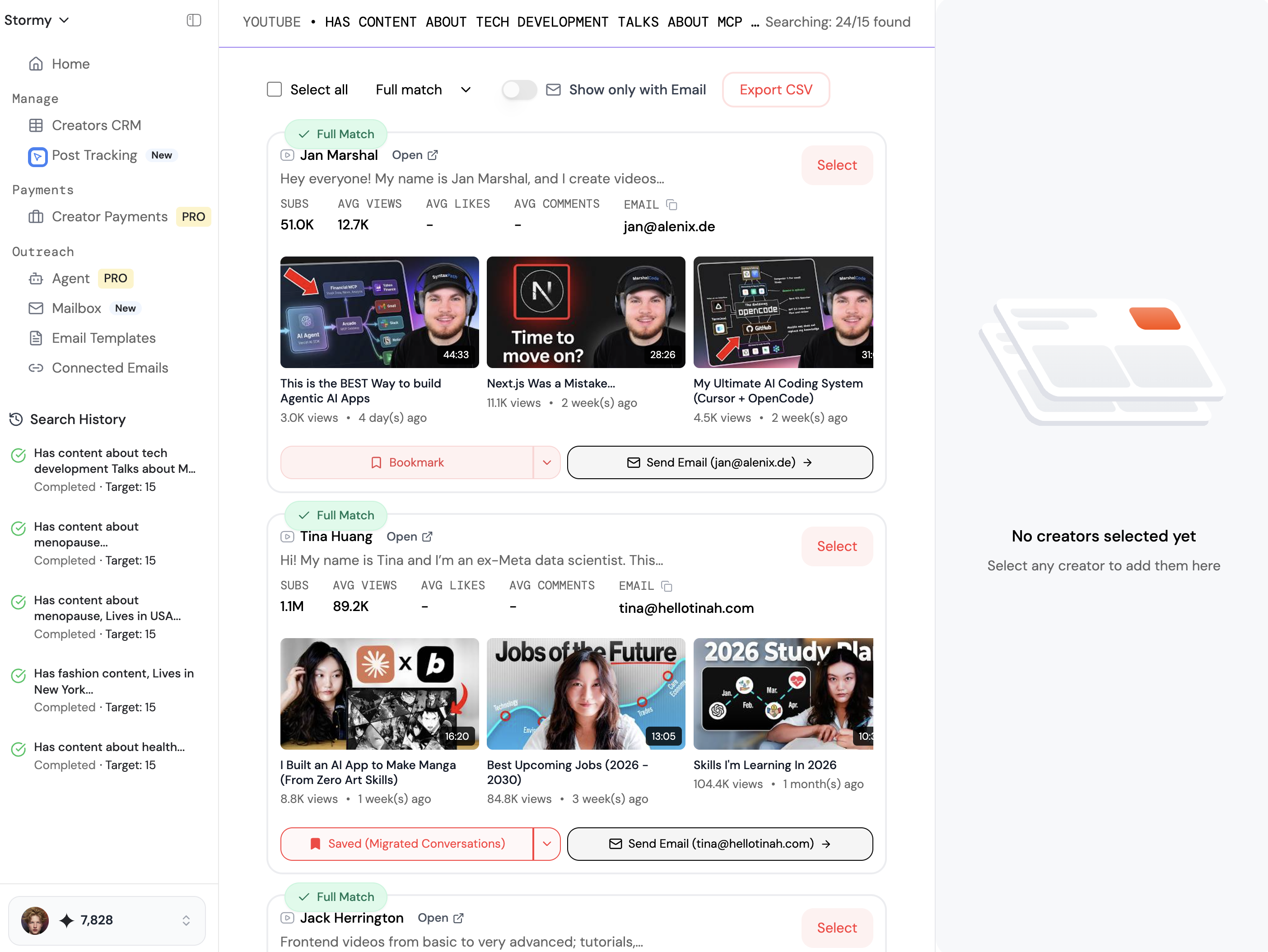
Managing 20 million API requests per month requires more than just good code; it requires operational discipline. When your API is the backbone of another company's product—like the infrastructure used for influencer analysis and vetting on Stormy AI—you cannot afford outages. Monitoring is key. Many solo developers hire dedicated support or monitoring staff in different time zones, such as the Philippines, to ensure that if a scraper breaks in the middle of the night, someone is there to investigate immediately.
Credit-Based Pricing Models
Most scraping APIs move away from traditional monthly subscriptions and toward a credit-based model. This aligns your revenue directly with your costs. For example, a common pricing structure might look like this:
- $10 for 5,000 credits (Basic experimentation)
- $50 for 25,000 credits (Growing startups)
- $500 for 500,000 credits (Enterprise-level data needs)
Legal and Ethical Considerations: Scraping Public Data

When building a social media scraping api, staying on the right side of the law is paramount. The consensus among successful developers is to focus exclusively on publicly available data. This includes profile statistics, public posts, and engagement metrics that any user could see without logging in. Scraping private user data or bypassing privacy settings is not only a violation of terms but also puts the developer at significant legal risk.
Furthermore, many developers are expanding their reach by scraping ad libraries. Tools like the Meta Ad Library and the LinkedIn Ad Library provide a wealth of information for mobile app marketers and developers. By aggregating this data, you can help brands analyze competitor strategies and UGC (user-generated content) trends. This is particularly useful for companies looking to optimize their app install campaigns by seeing what creative assets are performing best for others in their niche.
The Scraping API Playbook: Step-by-Step
If you are a developer looking to break into the social media analytics space in 2025, follow this clear playbook to build and launch your API.
Step 1: Validate via Marketplaces
Don't guess what people want. Visit Acquire.com and filter for SaaS businesses in the web scraping niche. Look for listings with an asking price of $300,000 or more. This proves that there is a buyer for the business and a market for the service.
Step 2: Reverse Engineer the Competitor
Once you find a successful listing, use Google to find the actual website. Search for phrases from the listing description or look for 'alternative to [competitor name]' blog posts. Once you find their site, analyze their documentation to see which endpoints they offer—are they focusing on Instagram followers, TikTok comments, or YouTube views?
Step 3: Build the Infrastructure
Set up your node.js scraping tutorial environment. Use Render for your API and AWS Lambda for the scraping logic. Integrate proxy rotation for scraping using providers like Evomi to keep your costs low while maintaining high success rates.
Step 4: Focus on Reliability and Communication
The easiest way to beat established competitors is through better support. Give your customers a way to contact you directly. If an endpoint breaks (and it will), communicate that proactively. High-growth startups and platforms like Stormy AI (an all-in-one AI-powered platform for creator discovery and AI-personalized email outreach) value reliability above all else when choosing a data provider.
Step 5: Aggressive Outreach
Growth doesn't happen by accident. Monitor social media for developers complaining about their current scrapers. Offer free credits (e.g., 10,000 free credits) to anyone willing to try your API. Leverage SEO by creating content around specific use cases, such as how to scrape instagram data for influencer marketing or how to use UGC for mobile app growth.
Conclusion: The Future of Social Media Data
Building a social media scraping api is one of the most viable paths for a solo developer to reach a $20,000 monthly income. By focusing on social media analytics infrastructure that is reliable, scalable, and easy to use, you can carve out a significant niche in the marketing tech stack. The technical hurdles—from managing proxy rotation for scraping to scaling with AWS Lambda—are significant, but they also serve as a barrier to entry that keeps your competition at bay.
As you build, remember that the goal is to provide actionable data that helps brands grow. Whether they are using Stormy AI to track individual videos and monitor engagement or to audit their app store optimization strategy, your infrastructure is the engine that powers their success. Stop waiting for the 'perfect' idea and start executing on a model that is already proven to work. The data is out there—your job is just to build the bridge.