The landscape of software engineering just shifted under our feet. With the simultaneous release of Anthropic's Opus 4.6 and OpenAI's GPT-5.3 Codex, the barrier between an idea and a multi-billion dollar application has effectively vanished. We are no longer just talking about simple scripts; we are entering the era of automated software engineering with LLMs where entire platforms can be scaffolded, designed, and tested in under ten minutes. But as these models evolve, they are taking radically different approaches to how they build. In this AI app development case study, we follow veteran engineer and Bold Metrics co-founder Morgan Linton as he puts these titans head-to-head to rebuild a clone of the prediction market giant, Polymarket.
Philosophical Divergence: Autonomy vs. Collaboration
As noted in recent discussions on Hacker News, the two leading AI labs are diverging philosophically. GPT-5.3 Codex is positioned as the ultimate interactive collaborator. It is designed for mid-execution steering, allowing the developer to stay in the loop, course-correct, and pair-program in real-time. It functions like a brilliant founding engineer who works at breakneck speed but needs occasional guidance to stay on track.
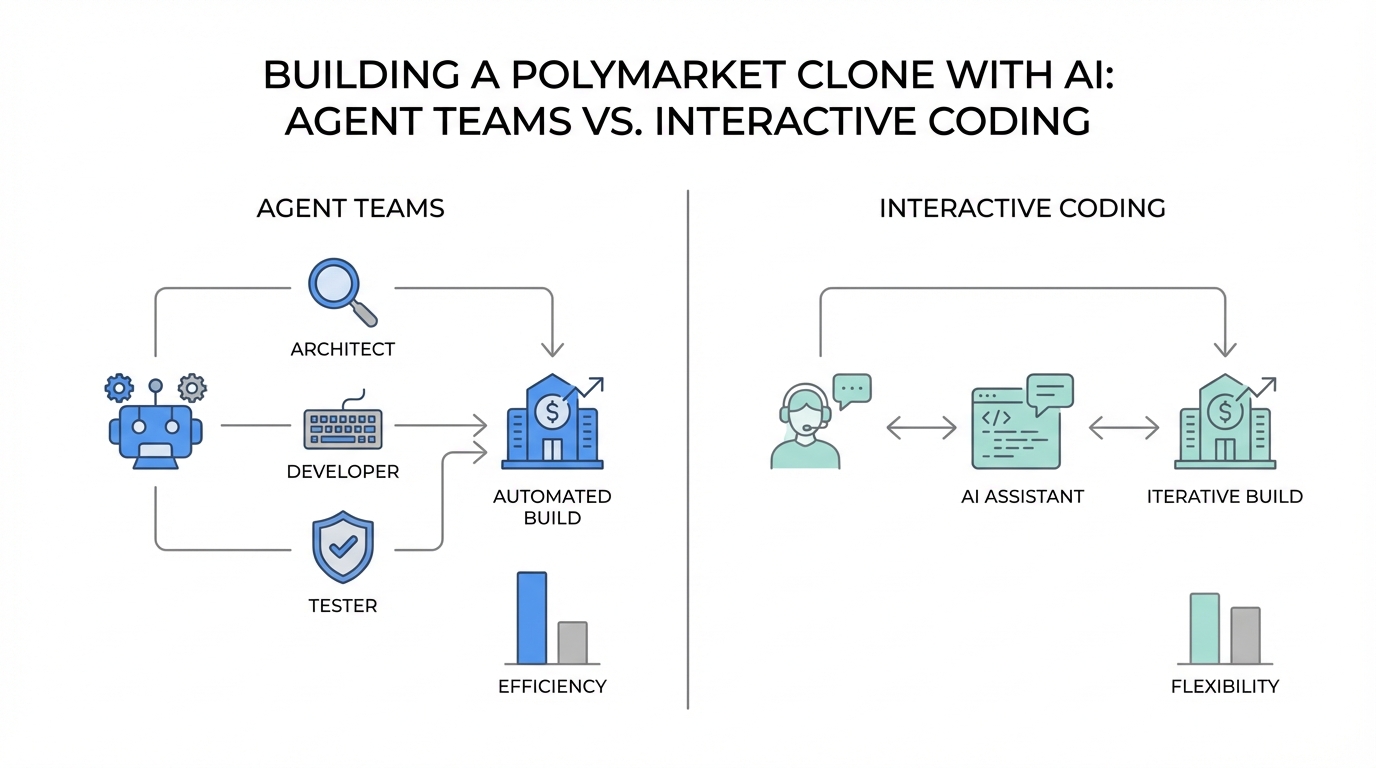
Conversely, Claude Opus 4.6 represents the shift toward autonomous agentic systems. Through its new Agent Teams feature, Opus 4.6 plans deeply, runs longer, and asks less of the human. It acts more like a senior staff engineer or a project manager who orchestrates a team of specialists to handle research, architecture, and QA before a single line of code is committed. This divergence is critical for anyone looking to build app with AI agents, as the choice of model now dictates your entire development methodology.
Step 1: Configuring Your AI Engine for Opus 4.6
Before diving into the code, you must ensure your environment is correctly configured to leverage the latest features. For Anthropic's newest model, the power lies in the CLI and the Agent Teams experimental feature. Follow this playbook to get started:
1. Update Your Environment
Ensure you are running the latest version of the Claude CLI. Run npm update followed by claude update. You should verify that you are on version 2.1.32 or higher. Running older versions will prevent you from accessing the 4.6 architecture and will likely yield inferior results.
2. Enable Agent Teams
This is the most significant addition to Claude Opus 4.6 use cases. You must manually enable this in your settings.json file. Navigate to your Claude directory and add the following environment variable: claude_code_experimental_agent_teams=1. Without this, the model will attempt to process tasks linearly rather than launching parallel research agents.
3. Leverage Adaptive Thinking
For API users, Opus 4.6 introduces Adaptive Thinking. By setting the effort level to max, you allow the model to think with no constraints on depth. This is specifically optimized for complex architectural decisions where total recall of the codebase is required. Unlike GPT's focus on progressive execution, Opus uses its 1-million token context window to reason over the entire repository at once.
The Polymarket Challenge: A Head-to-Head Comparison
To test these models, we chose to rebuild Polymarket, a platform requiring a complex matching engine, binary prediction mechanics, and a real-time order book. The prompts were kept nearly identical to ensure a fair vibe coding tutorial environment.
Claude Opus 4.6 was instructed to "build a competitor to Polymarket using an agent team to explore technical architecture, market mechanics, UX, and testing." GPT-5.3 Codex was given the same requirements but framed as a single-stream execution task, focusing on deep thought and clean implementation.
The Power of Parallel Agentic Orchestration
The difference in execution was immediate. Opus 4.6 launched four parallel research agents. One agent focused on Logarithmic Market Scoring Rule (LMSR) math, while another performed web searches to analyze the current Polymarket architecture. A third agent focused on UX design, and a fourth developed a testing strategy. By the time the code was being written, the system had already synthesized findings from over 100,000 tokens of research data.
GPT-5.3 Codex, however, optimized for speed. It began scaffolding the repository within seconds, wiring the core market math and trading engine almost instantly. It utilized its 200,000-token context window to act as a founding engineer, making rapid decisions and moving into a functional prototype in under four minutes. While GPT was faster to a working "Hello World," Claude was significantly more thorough in its preparatory stages.
Design and "Taste": The Jack Dorsey Test
In the world of vibe coding, "taste" is often the hardest thing for an AI to replicate. Initial outputs from both models were functional but visually bland. To push the limits, we prompted GPT-5.3 to "pretend you are Jack Dorsey and redesign this to be clean, elegant, and full of interesting interaction."
GPT-5.3 demonstrated its mid-execution steering capability here. We were able to pause the generation, confirm it understood the design aesthetic of Square and Twitter, and then resume. The result was a monochrome-first, interaction-driven interface. However, Claude Opus 4.6, despite being slower, produced a vastly more polished product out of the box. Its "Forecast" platform included hover states, purposeful motion, and pre-populated categories for sports, crypto, and AI—feeling less like an MVP and more like a production-ready application.
Technical Rigor: Why 96 Tests Matter
The most shocking metric of this AI app development case study was the difference in testing. For the exact same prompt, GPT-5.3 generated 10 unit tests, covering basic engine behavior and API integration. It passed with 10/10, providing a sense of security that the core math worked.
Claude Opus 4.6 generated 96 tests.
The dedicated QA agent in the Opus team didn't just test the engine; it tested edge cases in the order book, matching engine failures, and frontend routing. This level of automated software engineering with LLMs reduces the technical debt that usually accumulates during rapid AI prototyping. If you are building high-stakes financial applications, the rigor of Opus 4.6's agentic approach is a clear winner.
Scaling Your App with Modern Tools
Building the app is only half the battle. Once your Polymarket clone is live, the focus shifts to growth and liquidity. In the prediction market space, user-generated content (UGC) and influencer endorsements are the lifeblood of the platform. This is where tools like Stormy AI can help source and manage UGC creators at scale.
Using Stormy's AI-powered search and discovery, you can instantly find creators who specialize in crypto-economics or political commentary to drive traffic to your new markets. Just as Opus 4.6 automates the engineering, platforms like Stormy AI streamline creator sourcing and outreach, allowing you to manage your entire creator CRM and track post-performance without leaving the dashboard.
Token Usage and Performance Metrics

Efficiency in automated software engineering with LLMs comes at a cost. During the 10-minute build process:
- Opus 4.6 consumed between 150,000 and 250,000 tokens. With its Agent Teams, the usage multiplies by the number of active agents. For a $200/month Pro plan user, this is a negligible cost for a billion-dollar prototype, but it highlights how "token hungry" agentic workflows have become.
- GPT-5.3 Codex was significantly more conservative, focusing on progressive execution. While it lacked the parallel research depth, it provided a functional trading terminal with far fewer credits consumed.
When selecting your model, consider if your task requires total recall (Opus) or rapid iteration (GPT). For a prediction market where math must be verified via CoinMarketCap data or other external sources, the research-heavy approach of Opus 4.6 is often worth the extra token spend.
Conclusion: Choosing Your AI Teammate
This head-to-head demonstrates that there is no longer a single "best" model—only the best model for your specific AI app development case study. GPT-5.3 Codex is the speed demon, the perfect tool for the developer who wants to remain the primary pilot and use AI as a high-powered co-pilot. It excels in vibe coding where the developer's intuition guides the machine.
Claude Opus 4.6 is the staff engineer. It is the choice for teams looking to delegate entire workstreams, from research to 96-point test suites. By enabling Agent Teams, you aren't just using an LLM; you are managing a digital workforce. As you move from prototype to production, the rigor and "taste" of Opus 4.6 provide a foundation that is difficult to beat. Whichever you choose, the message is clear: the era of manual scaffolding is over. It's time to let the agents loose.