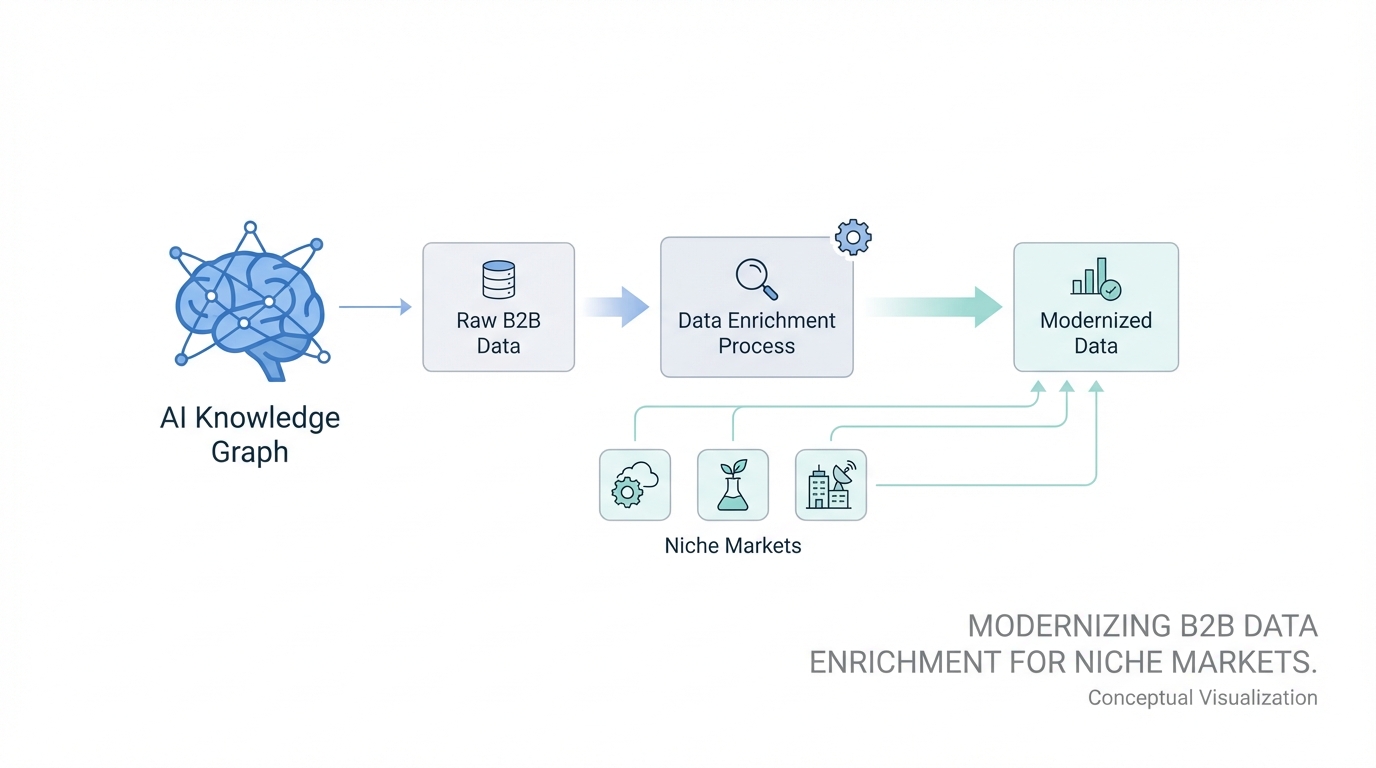
In the world of B2B growth, there is a universal rule that every entrepreneur should live by: anytime you see an industry relying on a messy spreadsheet to manage critical information, a lightbulb should go off. That spreadsheet is a glaring sign of a startup opportunity. For a decade, B2B lead generation software and data enrichment were dominated by static databases and rigid API lookups. If the data wasn't in the system, it didn't exist for your marketing team. But the landscape is shifting. We are moving away from the era of "static record lookups" and into the age of the AI Knowledge Graph, where Large Language Models (LLMs) turn the vast, unstructured ocean of the internet into precise, actionable marketing data.
The Limitations of Legacy Data Enrichment
For years, companies like Clearbit (recently acquired by enterprise software giants) served as the gold standard for data enrichment. You provided a domain, and they returned a set of fixed attributes: employee count, industry, and perhaps a headquarters location. While revolutionary at the time, this model has reached its ceiling. The problem with legacy data enrichment APIs is their lack of flexibility. You are restricted to the data points the provider chooses to track. If you want something unique—say, identifying companies that recently mentioned a specific pain point on a podcast—you are out of luck.
Furthermore, these legacy systems often struggle with accuracy in rapidly changing markets. According to industry research, when AI data enrichment processes were first introduced to these older data sets, accuracy rates jumped from a mediocre 30% to a staggering 95% accuracy. Static databases simply cannot keep up with the velocity of professional changes on platforms like LinkedIn or the insights buried within unstructured data extraction from video and audio content.
Beyond Static APIs: The Flexible Knowledge Graph
The modern alternative is a flexible knowledge graph API. Instead of a fixed table of data, this model treats the entire web as a queryable database. By indexing and embedding data from sources like YouTube, podcasts, news articles, and social media threads, businesses can create custom data points on the fly. This is the core of modern marketing automation tools: the ability to segment your audience based on what they are actually saying and doing right now, not just their job title from three years ago.
Imagine being able to query an API not just for "SaaS companies in New York," but for "Companies whose CEOs have discussed international expansion on a podcast in the last six months." This level of granularity is only possible when you move beyond the row-and-column constraints of traditional B2B lead generation software.
The 'Sri Lankan Real Estate' Test for Niche Markets
One of the most powerful strategies for competing in the data space is what we call the "Sri Lankan Real Estate" test. Massive data incumbents like ZoomInfo are incentivized to focus on the largest, most profitable markets—typically US-based tech and enterprise sectors. They often ignore highly specific niches. If you tried to build a B2B lead generation campaign for real estate developers in Sri Lanka using a legacy tool, you would likely find the data sparse, outdated, or non-existent.
However, an AI-powered enrichment pipeline can crawl local news, government records, and social directories to build a high-fidelity dataset for that specific niche in weeks. By arming the rebels—the smaller merchants and specialized agencies—with these tools, you create a competitive moat that the giants can't easily cross. This is how you win: by carving off a section of "power users" in a niche and building features specifically for their unique workflow.
Technical Execution: Building the Enrichment Pipeline
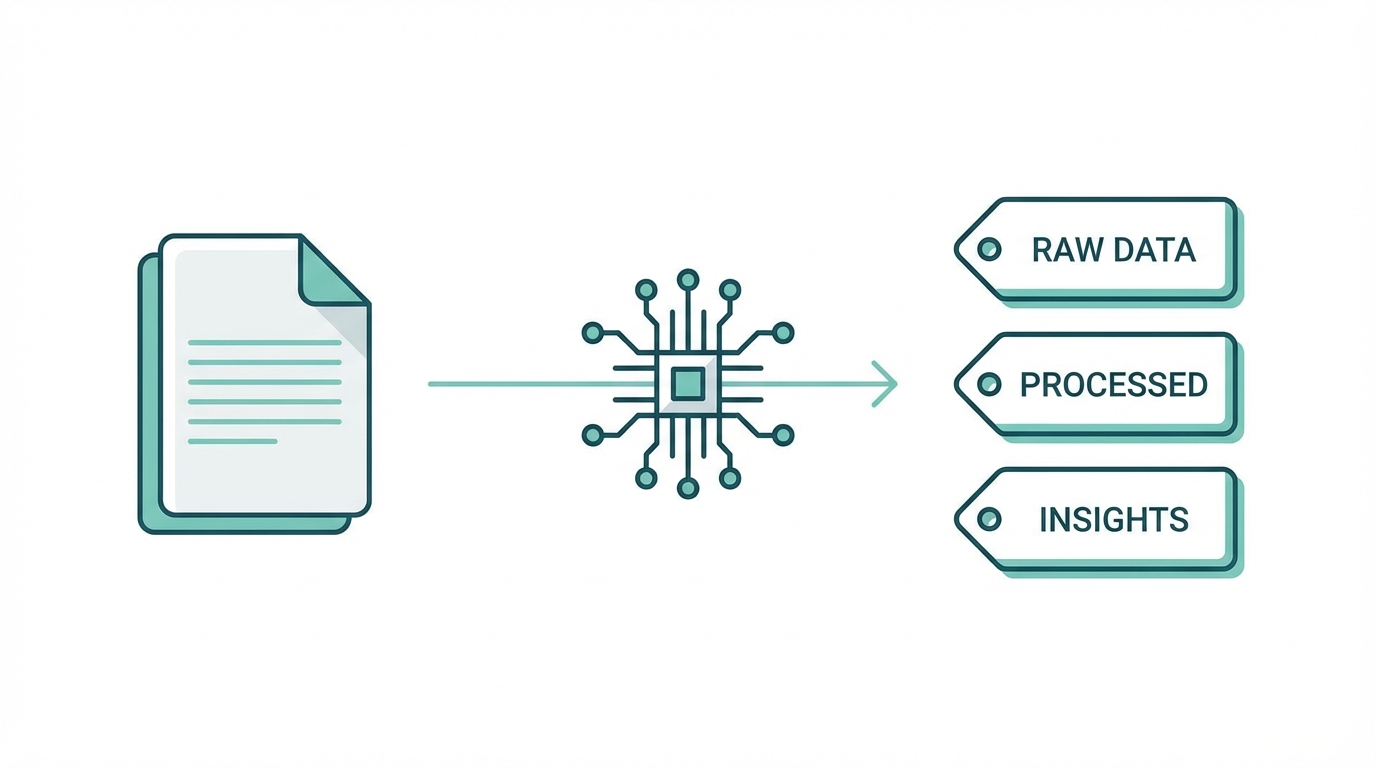
Building a modern unstructured data extraction pipeline involves several key stages. It isn't just about calling a single LLM; it's about the orchestration of data flow. To build a venture-scale or highly profitable bootstrapped data business, you generally follow this playbook:
- Data Ingestion: Use scrapers or system integrations to ingest unstructured data. This includes social media dumps, transcribing audio from podcasts, and parsing video content.
- Embedding: Convert this data into vector embeddings and store them in a data warehouse. This allows for semantic search—finding meaning rather than just matching keywords.
- LLM Parsing: Use an LLM to extract specific data points from the embedded content. This is where you achieve that 95% accuracy by asking the AI to verify claims across multiple sources.
- API Delivery: Deliver this data via a data enrichment API that allows users to request custom attributes on the fly.
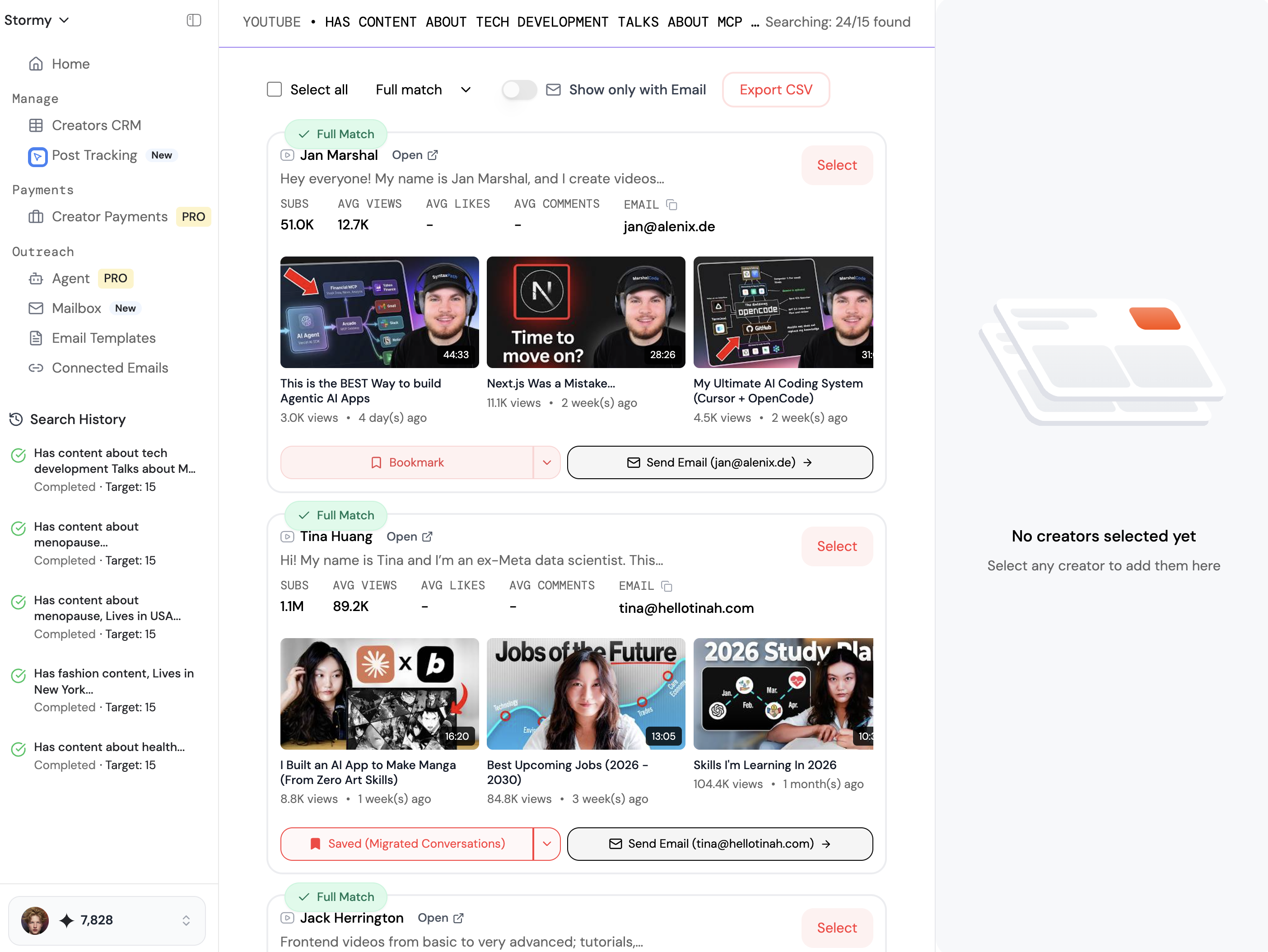
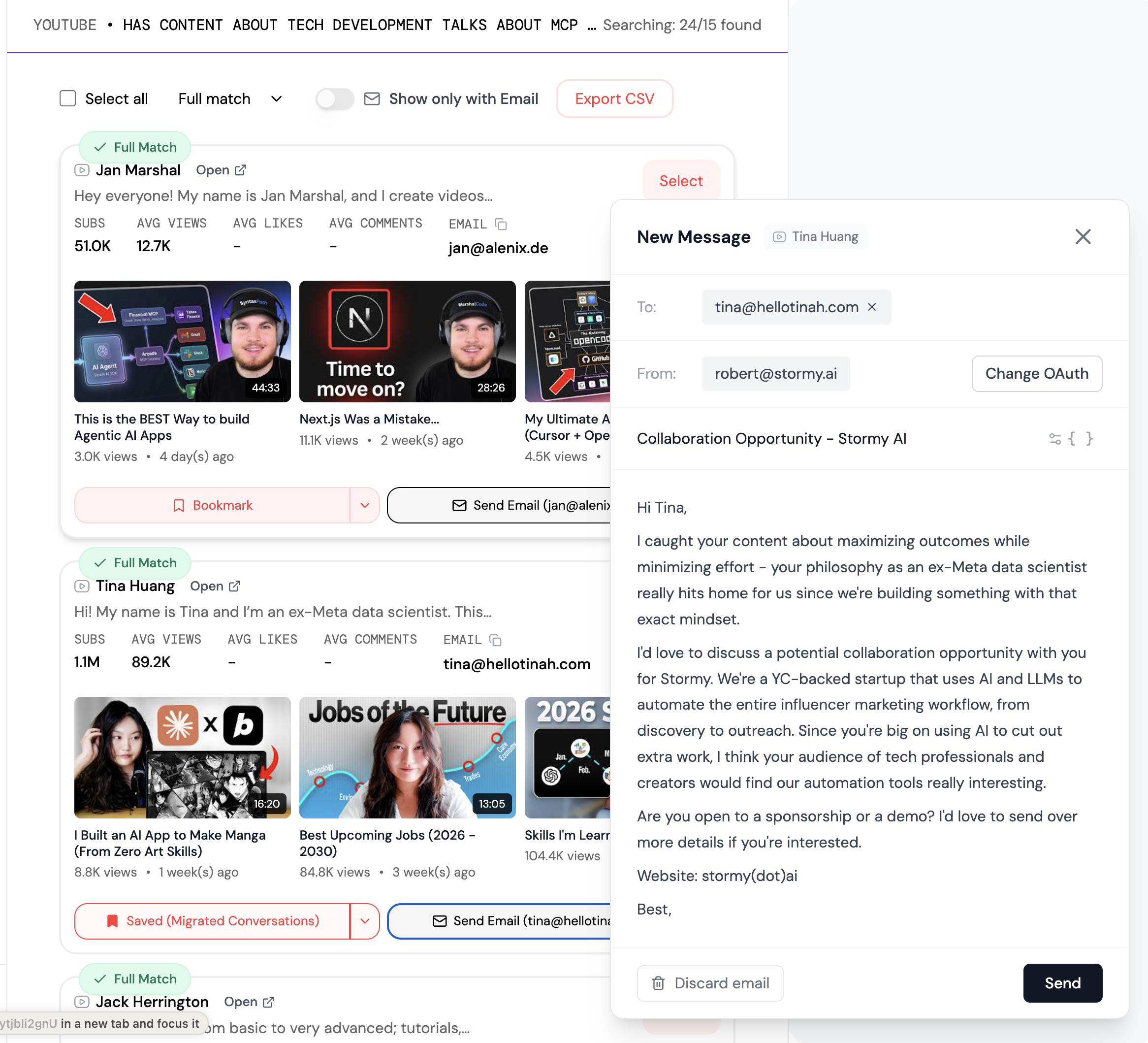
For marketing teams, this specialized data is gold. For example, platforms like Stormy AI utilize these advanced discovery techniques to help brands find niche creators across TikTok and YouTube by analyzing their actual content rather than just their surface-level profile stats. This ensures that the creators you partner with are a genuine match for your brand's voice and audience demographics.
Personalized Outreach and the Human Element
Data enrichment is only half the battle; the other half is marketing automation that doesn't feel automated. Once you have high-quality, enriched data—like knowing a prospect’s specific interests or recent public statements—you can generate hyper-personalized outreach. This eliminates the "negative selection bias" often found in cold outreach, where only the most desperate or low-quality leads respond.
When you have a directory of people with verified work history and interests, you can use AI to craft emails that reference specific moments from their career or content. Using an AI-powered creator CRM allows you to manage these relationships at scale, tracking every negotiation and interaction in one place, which is vital for long-term growth.
The Exit Strategy: Cash-Flow vs. Acquisition
How do you turn this into a successful business? There are two primary paths. The first is bootstrapping for cash flow. Data businesses are inherently lucrative because they can charge per enrichment. If you can charge 50 cents per contact and maintain low overhead using efficient LLM calls, reaching $30k - $50k MRR is entirely feasible without venture capital, as seen in communities like Indie Hackers.
The second path is acquisition by CRM giants. Legacy CRM leaders often buy data enrichment startups not just for their revenue, but for their capabilities. They want to provide data "out of the box" to their users to create a competitive moat. If you have built a superior knowledge graph for a specific niche, you become an incredibly attractive target for these platforms looking to bolster their internal intelligence.
Conclusion: The Linear formula for Data
The future of AI data enrichment follows what we call the "Linear formula." You don't need to invent a brain-exploding new technology. You simply need to take a core workflow—like lead discovery or market research—and build it simpler, more beautiful, and more performant than the 15-year-old incumbents. By focusing on unstructured data and niche markets, you can provide a level of value that static databases simply cannot match. Whether you are building a tool for Sri Lankan real estate or a global B2B lead generation software platform, the lightbulb moment remains the same: find the spreadsheet, apply the AI, and arm the rebels.