In the digital gold rush of the 2020s, the most valuable treasure isn't a proprietary algorithm or a massive user database—it is a file full of numbers. These numbers, known as model weights, represent the distilled intelligence of a Large Language Model (LLM) after months of compute-intensive training. When a company like OpenAI spends an estimated $500 million training GPT-4, that investment isn't just in code; it's in the specific configuration of weights that allow the model to reason. Unlike traditional software, where a stolen codebase is useless without a user base, stolen model weights can be deployed instantly by a competitor or a nation-state actor. As we move further into the age of generative AI, AI cybersecurity and machine learning data protection have become the new front lines of corporate and national security.
The Valuation Gap: Why Model Weights Are Different from Code
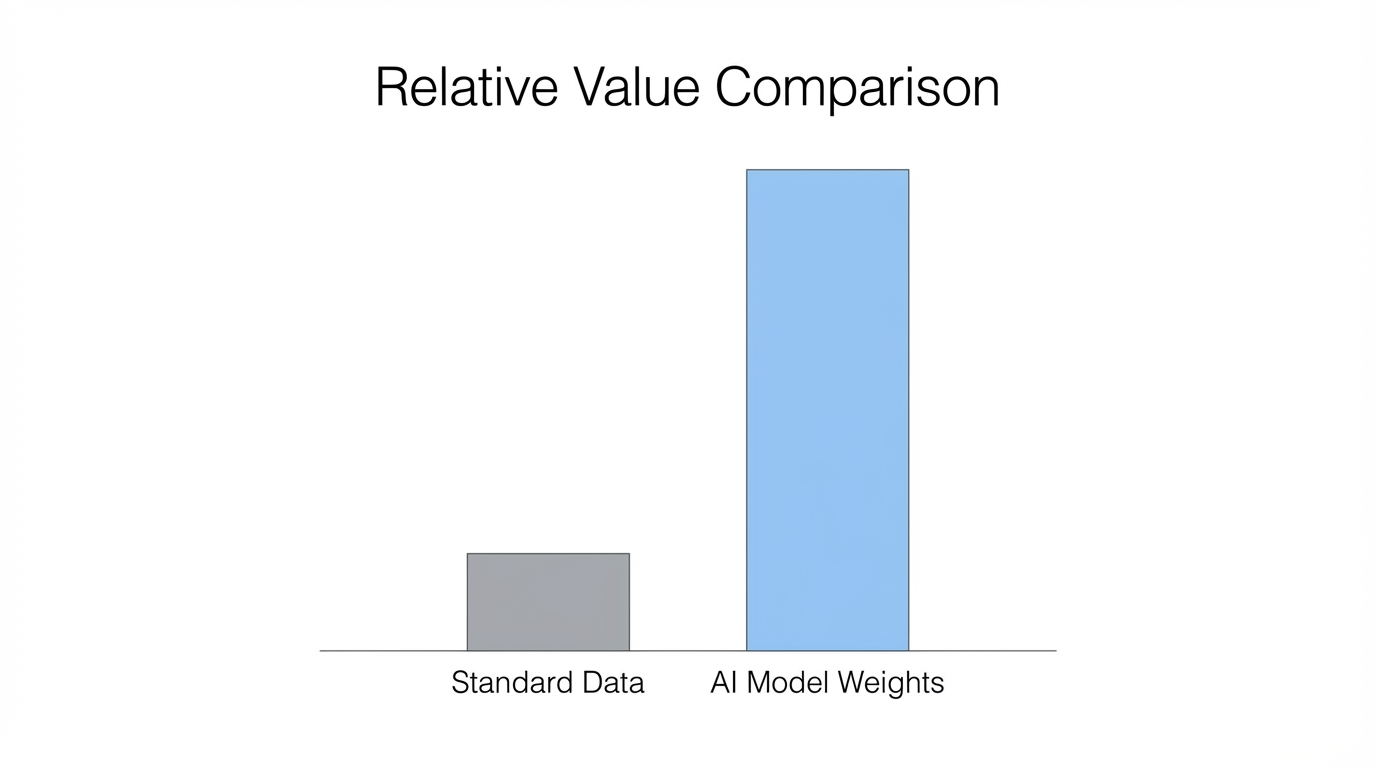
For decades, the crown jewels of tech companies were their source code and their network effects. If a hacker managed to exfiltrate the entire codebase of Facebook, they still wouldn't have a billion-dollar business. Why? Because the value lies in the users, the social graph, and the live data. You can't just launch "Facebook 2" and expect people to show up. However, large language model security faces a unique threat: the product is the model itself.
Once the GPUs go dark and the training run is complete, the entire capability of the AI is boiled down into weights stored in a database. Weights are highly portable. If an adversary steals the weights of a top-tier LLM, they can run that model on their own infrastructure, wrap it in a new UI, and immediately possess a world-class AI without the $500 million R&D cost. This makes protecting AI weights the highest-stakes challenge in modern AI security architecture, a topic now central to the OWASP Top 10 for LLMs. We are seeing a shift where model weights are treated not as intellectual property, but as high-value digital assets similar to private keys in cryptocurrency.
Lessons from Chainalysis: Indexing Growth Without Obsolescence
The burgeoning field of AI security can learn a vital lesson from the world of blockchain. When Bitcoin first emerged, many investors tried to pick winners among various tokens. However, the most consistent winners were service providers like Chainalysis. Chainalysis didn't need to launch its own coin; it built a high-cash-flow service indexed to the growth of the entire industry by helping law enforcement and financial institutions hunt down fraudsters.
Modern AI cybersecurity firms are taking a similar path. Instead of trying to build the next LLM, they are building the security layer that protects the labs. This model is uncorrelated to the success of any single model. Whether GPT-5 or a new open-source model becomes the industry standard, the need for machine learning data protection remains constant. By positioning as the "auditor" or the "shield," security startups can build sustainable businesses that aren't threatened by the next big architecture shift in AI.
A 5-Step Framework for Auditing AI Infrastructure

Protecting a model requires securing the entire pipeline, from the raw data to the inference API. If you are building or deploying AI, you need a rigorous AI security architecture. Here is a 5-step playbook for defending your digital assets:
Step 1: Secure the Training Data Supply Chain
Security starts before the first GPU is even turned on. Data poisoning is a significant risk where an adversary injects malicious data into your training set to create backdoors, as documented in the MITRE ATLAS framework. Use tools like Notion or internal wikis to document and verify every data source. Implement strict checksums and version control on all datasets to ensure the integrity of the training pipeline.
Step 2: Harden the Training Infrastructure
The environment where the model is trained is a massive target. This involves more than just standard firewalls; it requires hardware-level security. High-value training runs should occur in isolated environments with limited egress. Monitoring for unusual GPU utilization patterns can also help detect if a rogue process is attempting to exfiltrate weights mid-training.
Step 3: Implement Inference Layer Rate-Limiting
Many attackers don't try to steal the file; they try to reverse-engineer the weights through API queries. This is known as model extraction. By analyzing the probabilities of outputs, an attacker can eventually reconstruct a "student" model that mimics the original. Robust large language model security requires sophisticated rate-limiting and the detection of query patterns that look like extraction attacks.
Step 4: Use Differential Privacy and Weight Obfuscation
To prevent the weights from being easily interpreted if stolen, some firms are experimenting with weight obfuscation and differential privacy techniques. This ensures that even if a database is breached, the raw numbers are difficult to utilize without the specific proprietary "key" or transformation layer used by the original lab.
Step 5: Continuous Red-Teaming
The AI landscape changes weekly. AI cybersecurity isn't a "set it and forget it" task. Engage in continuous red-teaming where ethical hackers attempt to prompt-inject, extract, or bypass safety filters. Tech giants are already publishing their findings, such as the Microsoft AI Red Team reports. This is especially important for brands using AI in customer-facing roles, where a hallucination or an exploit can lead to massive brand damage.
The 'Insurance Wedge': A Market Entry Point

For many established brands, the fear of AI isn't just about theft—it's about reputational risk. Companies like Google Ads and Meta are increasingly moving toward generative AI for ad creative. While this increases performance, it terrifies CMOs at companies like Coca-Cola or Disney, who cannot risk a rogue AI generating an offensive image or a false claim.
This creates a massive opportunity for the "Insurance Wedge." Rather than just selling software, new startups can sell brand-protection insurance. If an AI-driven campaign causes a PR disaster, the insurance firm covers the cost of the brand correction. This is a brilliant way to sell to laggards who are nervous about adoption. To mitigate these risks, many savvy marketers use a hybrid approach: they use AI for efficiency but rely on vetted human creators for brand-safe content. Platforms like Stormy AI allow brands to discover and manage UGC creators who provide that authentic, human-verified touch, ensuring that the brand voice remains consistent even as AI-generated ads scale.
Defending Against State-Sponsored Data Exfiltration
We are no longer just dealing with independent hackers; we are dealing with nation-state actors. There are persistent rumors in Silicon Valley that foreign entities have already attempted to exfiltrate weights from major labs. When the national security of a country depends on AI dominance, the training runs of companies like Anthropic or OpenAI become military-grade targets.
Future-proofing against this requires a transition to Zero Trust AI architectures. This means no user, even internal developers, should have unfettered access to the full model weights. Implementing multi-party authorization for weight access—where two or more authorized officers must provide keys to move or export the model—is becoming a standard for protecting AI weights. Furthermore, air-gapping the final inference models from the development environments can prevent lateral movement by attackers who have breached the corporate network.
Conclusion: The Future of Model Defense
As the barrier to entry for training massive models continues to rise, the value of the resulting weights will skyrocket. AI cybersecurity is moving from a niche subfield to a foundational pillar of the tech stack. Companies must treat their model weights with the same level of security they would accord to Fort Knox or a Bitcoin cold wallet.
For founders and security professionals, the path forward is clear: build security that is indexed to AI growth, focus on the insurance wedge to win over risk-averse enterprise clients, and implement a multi-layered AI security architecture. Whether you are managing your own training runs or using tools like Stormy AI to track the performance of your creator-led campaigns, vigilance is the only true defense in the rapidly evolving AI landscape. The companies that survive the next decade won't just be the ones with the smartest models—they will be the ones who kept their models the most secure.